










1. Informations et connaissances 1.1. Définitions générales 1.1.1. Abréviations, Chose, Objet|Information 1.1.2. Information: données vs. connaissances 1.1.3. Exemples de représentations de connaissances 1.1.4. Lexical/structurel/sémantique 1.1.5. ID/phrase formel(e)/semi-formel(le)/informel(le) 1.1.6. Base de données/connaissances 1.1.7. Bases d'informations NoSQL 1.2. L'intérêt d'utiliser des BCs au lieu de BdDs 1.3. Vrais/faux problèmes liés aux BCs 1.3.1. Vrais problèmes liés aux BCs: les difficultés de les créer 1.3.2. Faux problèmes liés aux BCs: ceux liés à l'expressivité/efficacité 1.4. Inférences et organisation – relations particulièrement importantes: généralisation, implication, égalité, exclusion, member, part, correction 1.4.1. Inférences : déduction, abduction, induction, analogie 1.4.2. Organisation de RCs par égalité 1.4.3. Organisation de RCs par généralisation/implication/exclusion 1.4.4. Exemples de corrections additives 1.4.5. Types de concept de plus haut niveau essentiels 1.4.6. Types de relation essentiels - Graphique 1.5. Tâches dites "de gestion de connaissances" et leurs supports 1.6. Web 2.0/3.0/sémantique, web de données/connaissances 1.7. Exemples de langage de requêtes pour rechercher des RCs 1.7.1. Langage générique pour rechercher des RCs 1.7.2. SPARQL 1.8. JSON, JSON-LD, RDFa et micro-formats/data 1.9. Stockage et exploitation d'informations dans les réseaux neuronaux 2. Données 2.1. Types de données et normalisation lexicale des noms de variables+fonctions 2.1.1. Types de données les plus généraux 2.1.2. Quelques types de nombres 2.1.3. Quelques types de collections|conteneurs 2.1.4. Fonctions: normalisation lexicale, ... 2.2. Unicode, UTF-8 et séquences d'échappement 2.3. Exemples d'encodages de données pour des appels de fonctions via un réseau 2.4. Requêtes sur du HTML/XML: CSS/XSL(T), XPath/XQuery (+ XLink/XPointer) 3. Annexes: exemples de représentations de connaissances plus expressives CM1 (données/connaissances): sections en italique ci-dessus CM2 (BCs/BDDs+inférences): sections 1.1.6 à 1.4.3 (incluse) CM3 (Webs,RIs,types,finDeLaSection2): sections 1.4.4 à 1.9, puis 2.2 (nécessaire au TD+TP3) à 2.4 CM4 (requêtes conceptuelles): correction du 1er Devoir Maison, Wooclap (P3: 2.1.4 + R.I.), 1.7 et synthèse (préparez vos questions) CM5 (devoir: CC1) Note : dans ce document, pour naviguer vers une autre page, utilisez les flèches de votre clavier (ou la barre d'espace pour la page suivante) ; l'aide en bas à gauche de cette fenêtre donne plus de détails.
E.g.
(latin: exempli gratia): "par exemple".
I.e. (latin: id est):
"c'est-à-dire".
Vs.: "versus".
/: "ou bien" ( "ou" est non-exclusif, par défaut).
|: (quasi-)"alias" (entre 2 termes, dans le contexte où
ils sont définis).
Rappel:
Chose [thing]: tout ce à quoi quelqu'un peut penser est une chose.
Donc, tout ce qui est (implicitement ou explicitement) logiquement quantifié est une chose.
E.g.: ce à quoi réfère les mots "une ville" ("une": quantificateur existentiel,
"il existe au moins une"), "Londres", "3 personnes".
Objet d'information (ou simplement, en informatique, "objet")
[(informational) object, resource]:
(groupe de) symbole(s)|identificateur(s)|identifiant(s)|mot(s) référant à une chose (ou donc à plusieurs).
S'il y a un groupe (décomposable), la composition suit une
syntaxe (formelle ou informelle).
L'informatique [Information Technology (I.T.)] réfère aux techniques de stockage et traitement d'objets d'informations via des machines.
QW (question via Wooclap; cf. "P1wooclap" in Moodle) "Les objets d'...".
Dans ce cours, compte tenu des définitions adoptées pour les termes
"donnée" [data] et
"connaissance" [knowledge] (cf. ci-dessous), le terme
"Objet d'information" (défini ci-avant)
est leur généralisation:
Objet d'information = donnée ou bien connaissance.
Cette définition est compatible avec la majorité des interprétations générales usuelles
des termes
"information", "donnée" et "connaissance":
Cette définition n'est pas compatible avec d'autres définitions souvent moins précises de ces 3 termes, e.g.:
(Représentation de) connaissance (RC) [knowledge (representation)]:
information qui est,
au moins partiellement, représentée et organisée
Une RC est une affirmation (information), pas juste une expression, mais peut contenir des expressions définies avec des RCs.
Les 2 pages suivantes donnent des exemples de RCs.
Donnée [data]: information qui n'est pas une RC.
Une RC peut être une affirmation (information) (e.g., la phrase informelle "les chats sont gris")
ou bien une expression (e.g., l'expression "2 kg", le chiffre "2", une suite de sons, une image).
Base|répertoire d'informations
[information repository]:
base de données (BdD) [database (DB)] ou bien
base de connaissances (BC) [Knowledge Base (KB)].
Système de gestion d'information:
système de gestion de BdDs (SGBD) [DBMS] ou bien
système de gestion de BCs (SGBC) [KBMS] ;
attention (cf. section 1.5), la plupart des
"systèmes à base de connaissances" (SBCs) et des
"systèmes de gestion de connaissances" (SGCs)
sont des SGBDs et non des SGBCs tels qu'ici définis.
En: By definition, a flying_bird_with_2_wings is a bird that flies and has two wings.
PL: Flying_bird_with_2_wings (b) :=
Bird(b) ∧ ∃f Flight(f) ∧ agent(f,b)
∧ ∃w1,w2 Wing(w1) ∧ Wing(w2) ∧ part(b,w1) ∧ part(b,w2) ∧ w1!=w2
FE: any Flying_bird_with_2_wings is a Bird that is agent of a Flight and
has for part 2 Wing.
FE: any Flying_bird_with_2_wings is instance of ^`Bird that is agent of a Flight and
that has for part 2 Wing´
FL: any Flying_bird_with_2_wings type: ^(Bird agent of: a Flight, part: 2 Wing)
FL: Flying_bird_with_2_wings = ^(Bird agent of: a Flight, part: 2 Wing).
FL: Flying_bird_with_2_wings type _[any -> .]: ^(Bird agent of: a Flight, part: 2 Wing).
FL: Flying_bird_with_2_wings type _[any ?fbw2w ^-> .]: Bird, agent of _[?fbw2w ^-> a]: Flight,
part _[?fbw2w ^-> 2]: Wing.
RDF+OWL2 / Turtle: // langage (ici "modèle et notation") cité parce qu'actuellement souvent utilisé
:Flying_bird_with_2_wings owl:intersectionOf
(:Bird [a owl:Restriction; owl:onProperty :agent; owl:someValuesFrom :Flight]
[a owl:Restriction; owl:onProperty :wingPart; owl:qualifiedCardinality 2]);
| UML_model / UML_concise_notation: |  |
Notes :
QW P1wooclap "Lecture"+"Any Man/ID ...".
En: On March 21st 2016, John Doe believed that in 2015 and in the USA,
at least 78% of adult healthy carinate birds were able to fly.
FE: ` ` ` ` `at least 78% of Adult Healthy Carinate_bird is able to be agent of a Flight´
at place USA´ at time 2015´ for believer John_Doe´ at time 2016-03-21´.
FL: [ [ [ [ [at least 78% of Adult Healthy Carinate_bird is able to be agent of: a Flight ]
place: USA ] time: 2015 ] believer: John_Doe ] time: 2016-03-21 ].
FL: [ [ [ [ [Adult Healthy Carinate_bird agent of _[at least 78% can -> a]: Flight ]
place: USA ] time: 2015 ] believer: John_Doe ] time: 2016-03-21 ].
IKLmE / Turtle:
[rdf:value
[rdf:value
[rdf:value
[rdf:value
[rdf:value [rdf:value [:agent_of [a :Flight]
]; pm:q_ctxt [quantifier "78to100pc";
rdf:type :Adult, :Healthy,
:Carinate_bird ]
]; pm:ctxt [:modality :Physical_possibility]
]; pm:ctxt [:place :USA]
]; pm:ctxt [:time "2015"]
]; pm:ctxt [:believer :John_Doe]
]; pm:ctxt [:time 2016-03-21] ].
La
solution pour le TD2 donne un autre exemple
de "représentation de phrase utilisant des contextes".
La partie 3 de ce document (→ les annexes)
donne de nombreuses autres "représentations de phrases, sans contextes".
Des exemples pour l'organisation de types sont aussi référés en fin de la page suivante.
Voici quelques équivalences relatives à l'usage des contextes:
[S r1: D1 D2] <=> [S r1: D1, r1: D2].
[S1 r1: (S2 r2: D2)] !<=> [S1 r1: [S2 r2: D2]].
//[S2 r2: D2] is a sentence/situation, while (S2 r2: D2) is not
[[S1 r1: D1] r2: D2] <=> [S1 r1 _[r2: D2]: D1]
[any Hat color: a Red] <=> [Hat color _[any->a]: Red].
[Joe believer of: D1] <=> [Joe believer of _[.->.]: D1]
FL-DF: Human_being FL: Human_being Man↙s £ s↘ Woman subtype: Woman ↓i ( Man exclusion: Woman, Sean_Connery instance: Sean_Connery ).
Legend. "-s→": subtype; "-i→": instance; "£": exclusion
Quelques équivalences (représentées en FE puis en FL ;
une variable dont le nom est
préfixé par '^' est implicitement quantifié universellement,
c'est utile pour alléger l'écriture de règles représentées avec "<=>" ou "=>") :
FE: `^t has for subtype ^st´ <=> `^st is subtype of ^t´ <=> `every ^st is instance of ^t´ <=> ` `^i has for type ^st´ => `^i has for type ^t´ ´.
FL: [^t subtype: ^st] <=> [^st subtype of: ^t] <=> [^t ↘ ^st] <=> [^t \. ^st] <=> [^st supertype: ^t] <=> [^st ↗ ^t] <=> [^st /^ ^t] <=> [ [^i instance of: ^st] => [^i instance of: ^t] ] <=> [ [^i type: ^st] => [^i type: ^t] ] <=> [ [^i |^ ^st] => [^i |^ ^t] ] <=> [ every ^st |^ ^t ] <=> [ [^st instance: ^i] => [^t instance: ^i] ] <=> [ [^st |. ^i] => [^t |. ^i] ] //informellement : "^st est sous-type de ^t ssi toute instance de ^st est aussi instance de ^t"
FL: [ ^t \. partition{ ^st1 ^st2 } ] <=> [ ^t \. p{ ^st1 ^st2 } ] //une partition de sous-types pour un type ?t // est un ensemble de sous-types exclusifs qui est complet pour ?t, i.e. // toute instance de ?t est instance d'un des sous-types listés
Notes :
- Les 2 pages précédentes et la section 1.4.2 illustrent les différences entre
les différents quantificateurs universels non numériques:
[ `every' = `∀', \. `any' `each' ]
//"any" est pour les définitions, "each" est pour les observations
donc on a aussi : [ `a' \. (`each' = `100%') ].
Rappel : [ `a' = `∃' 'at least 1' `1..*' ]
- L'extension d'un type est l'ensemble de ses instances.
- L'intension d'un type, i.e. sa signification, est représentée via ses
"définitions par conditions nécessaires et/ou suffisantes".
Comme spécifié implicitement dans les pages précédentes
– et explicitement lors des explications orales en CM –
il y a deux sortes de "types" (→ les choses qui peuvent avoir une instance) :
subtype et time) → quand une RC est vue
comme un graphe, ce sont les types utilisés dans les (nœuds) relations, i.e. les
nœuds du graphe qui relient les autres nœuds (les nœuds concepts) ;
Bird et Class) sont utilisés dans les
nœuds concept.
Les nœuds concepts (ou les termes utilisés dans ces nœuds) peuvent
aussi référer à des "individus", e.g. à "Paris (la capitale de la France)". Contrairement à un type,
un individu ne peut pas avoir d'instance (mais il peut néanmoins être spécialisé, e.g.
"Paris (la capitale de la France) dans les années 1950".
Les types d'ordre 1 (e.g. Bird) sont les types qui ont des individus pour instance.
Les types d'ordre 2 (e.g. Class) sont les types qui ont des types d'ordre 1 pour instance.
C'est pourquoi, les "individus" sont parfois (extrêmement rarement) aussi appelés "types d'ordre 0".
L'usage de FL – ou d'autres notations, e.g.
UML –
pour l'organisation de types
a été introduit dans le cours "Projet HTML" en L1 Informatique :
(ré-)étudiez
cette page et
celle-ci, ainsi que
cette section.
L'organisation de types est le focus du TD 1.
C'est une étape essentielle de tout projet en informatique. Elle est souvent immédiatement
complétée par des représentations complémentaires, e.g. avec
OCL si UML est utilisé.
Cette étape peut permettre de
générer un programme
si tel est le but (i.e., si le but n'est pas d'organiser les informations d'une
base de données/connaissances).
Cette étape peut aussi permettre de
vérifier formellement des programmes.
Dans les deux cas, un
langage de spécifications formelles
est utilisé (dans ce dernier document pointé, voir la liste des langages les plus connus
– en particulier Z et CASL – et la liste des "assistants de preuves", en particulier
Rocq ;
OCL peut être vu comme le langage de spécifications formelles généralement associé à UML).
La section 1.4.4 montre une organisation (en FL) des types de concept de plus haut niveau essentiels.
Lisez ce document qui organise (en FL) différentes notions de littératie [literacy].
Ce document sur les relations et interfaçages entre ontologies et d'autres approches/outils
donne (entre autres) de nombreux
exemples "d'organisation de types" (cf. page suivante + TD 1) en FL.
Ce dernier document n'est pas à lire si vous ne le souhaitez pas.
Lexical: relatif à la décomposition d'un (groupe de) mot(s)|symbole(s) en ses(leurs) composants, généralement des lettres. E.g.:
Structurel: relatif à
Sémantique: relatif à une RC, i.e. à une représentation (partielle/totale)
du ou des sens d'un objet.
Phrase(déclarative)|formule|RC|description [(declarative)sentence|formula|KR|declarative statement]: "groupe de mots|symboles" (→ objet d'information structuré) qui peut-être affirmé ou nié et donc qui dénote|représente une "situation" (i.e., soit un état, e.g. "Jean est assis" et "il existe des objets physiques", soit un processus, e.g. "Jean marche"). C'est donc aussi quelque chose qui a ou peut avoir une valeur de vérité (e.g., vrai ou faux) mais d'autres choses peuvent avoir une valeur de vérité, e.g. les variables booléennes.
Expression: (groupe de) mot(s)|symbole(s) (→ objet d'information) qui
n'est pas une phrase
(en logique et en informatique, une expression est aussi appelé un "terme").
Un identificateur|identifiant (ID) est une expression atomique, i.e. non composé.
Un identificateur de phrase est un ID qui réfère à une phrase.
Interprétation/sémantique basée sur des modèles
(une des méthodes formelles pour définir une sémantique): fonction associant
- chaque expression ("terme" au sens logique) utilisée à une chose, et
- chaque "phrase|formule|RC" à une valeur de vérité.
Terme/phrase formel(le):
terme (expression, e.g. un ID via un symbole) ou phrase ayant
– par convention, déclaration ou construction –
un sens unique.
Techniquement, un identifiant est soit un "identifiant unique" (-> formel),
soit just un "mot"|"nom" (-> informel).
Toutefois, par défaut (et ce sera désormais le cas dans ce cours), il est d'usage que
"identifiant" (ID) réfère à "identifiant unique".
Exemple d'ID: un mot-clé dans un langage formel, un identificateur dans un programme.
Exemple d'expression formelle composée: une expression syntaxiquement correcte composée
d'expression formelles plus élémentaires (jusqu'à arriver à des IDs).
Attention, un sens particulier peut avoir de nombreux IDs (ayant chacun un
sens unique, donc le même sens unique, le sens particulier en question).
Phrase|RC|description formelle: RC composée uniquement d'IDs formels.
RC partiellement formelle: RC incluant des IDs formels et d'autres informels (des mots).
Syntaxe formelle:
syntaxe|grammaire composée de termes (expressions) formels et selon laquelle
les termes non-terminaux|composés|structurés se décomposent en termes primitifs|terminaux.
BC: ensemble d'identifiants (uniques ou pas) et de RCs les utilisant
parties: |
|
BdD [DB]: base d'informations qui n'est pas une BC.
parties: |
|
sous-types: |
- BdDs relationnelles/orientées-objet/déductives/associatives/... Notes: i) une "BdD RDF" est en fait une BC; ii) plus un SGBD (ou langage formel) est expressif, et plus sa base est normalisée, plus il se rapproche d'un SGBC. - documents XML/JSON/Latex - base de documents qui ne sont pas de BCs - données indexées par des identificateurs provenant de folksonomies / ontologies (e.g. comme dans les wikis sémantiques); Linked data – e.g. le Web Sémantique – réfère à un ensemble de BCs et aux données que ces BCs indexent ou relient). |
Les systèmes/modèles de gestion d'informations
"non-relationel"
["not only SQL" (NoSQL)]
sont des SGBDs non-relationels ou des SGBCs. E.g.:
La possibilité de
QW P2wooclap "Une BD ...", "un SGBD ...", "Organiser ..."
Documents à lire : Cyc,
ConceptNet,
UMBEL (maintenant remplacé par
KBpedia),
Freebase
(le 1er document et, partiellement, le second sont liés à la notion de
"base de connaissances du sens commun" ; dans le 1er document, l'expression "base de données" réfère en fait à la "base de connaissances" de Cyc).
Une BC, une fois construite, a beaucoup d'avantages par rapport à une BdD (sauf sur des critères de performances lorsque les types de requêtes sont connus) MAIS, comme créer un programme, créer une BC (ré-)utilisable est difficile !
Comme toujours : garbage in, garbage out !
Tout d'abord quelques rappels.
Logique d'ordre 0 (alias, logique propositionnelle): logique n'ayant pas de variable (quantifiée).
Logique d'ordre 1 (alias, logique des prédicats,
un type de prédicat étant assimilable à
un type de relation unaire ou non,
ou encore à un type de concept ou un type de relation):
logique ou seuls les individus (explicitement nommés ou anonymes) peuvent
être quantifiées (et donc mis dans des variables),
e.g., la définition suivante est une "phrase du 1er ordre" et nécessite une logique du
1er ordre.
En : the ancestor of an ancestor is an ancestor (i.e. "ancestor" is transitive) PL : ∀?x ∀?y ∀?z (ancestor(?x,?y) ∧ ancestor(?y,?z)) => ancestor(?x,?z)
Logique d'ordre 2 ou plus (alias, logique d'ordre supérieur): logique où les types de
relation peuvent
être mis dans des variables.
E.g., la définition suivante est une "phrase du 2nd ordre" et requiert
une logique du 2nd ordre
car elle comporte un quantificateur universel sur des types de relations.
En : ?r is a owl#Transitive_property ?r iff ?r(?x,?y) and ?r(?y,?z) implies ?r(?x,?z) PL : ∀?r owl#Transitive_property (?r) <=> ∀?x ∀?y ∀?z ( ?r(?x,?y) ∧ ?r(?y,?z) ) => ?r(?x,?z) FL : owl#Transitive_property (?r) := [ [^x ?r: ( ^y ?r: ^z )] => [^x ?r: ^z] ]; //^x, ^y et ^z are free variables, i.e., implicitely universally quantified FL : [__ every pm#relation ?r, every pm#thing ?x, every pm#thing ?y, every pm#thing ?z] [ [owl#Transitive_property ?r] <=> [ [?x ?r: (?y, ?r: ?z)] => [?x ?r: ?z] ] ]; Notes: - définir la transitivité requiert une logique d'ordre 2 (→ 2nd-ordre) mais, comme illustré ci-dessus, définir une relation transitive particulière (e.g., subtype) ne requiert pas une logique du 2nd-ordre ; - seules certaines logiques du 2nd-ordre (e.g., logiques modales, logiques temporelles) permettent de raisonner sur certaines phrases contextualisées (e.g., phrases contextualisées dans le temps) mais écrire des méta-phrases non-contextualisantes ne requiert pas une logique du 2nd-ordre ; - exemple de moteurs d'inférences du 2nd-ordre: Rocq (home page), Hets , Isabelle, HOL Light, ACL2 ; - exemple de raisonnement nécessitant une logique modale: celui de cette "preuve ontologique de l'existence de Dieu" qui pré-suppose que certaines propriétés de Dieu existent nécessairement.
Notation du 2nd-ordre: notation permettant d'utiliser des variables pour les relations/prédicats et de les quantifier.
Une notation du 2nd-ordre n'implique pas nécessairement un moteur d'inférence du 2nd-ordre
pour l'utiliser, en particulier si les phrases du 2nd-ordre sont des définitions.
En effet, il n'existe souvent qu'un nombre fini de catégories de 1er ordre
concernées par ces définitions et il est alors souvent possible
d'instancier (i.e. appliquer) la définition du 2nd-ordre à ces catégories
(e.g., instancier la notion de transitivité à chaque relation transitive).
Le moteur d'inférences peut alors ne pas prendre en compte la définition
du 2nd-ordre.
Plus généralement, l'expressivité d'une BC - et donc ses caractéristiques vis à vis des
critères de complétude des raisonnements qui peuvent être effectués
via cette BC - n'est pas "déterminée" par la notation utilisée pour
rentrer les informations dans cette BC.
De plus, un moteur d'inférences peut toujours choisir de ne pas utiliser toutes les informations de la BC. Il sera alors plus efficace mais ses résultats pourront être incomplets ou non toujours valides. C'est un choix qui ne peut être fait que dans le contexte d'une application. E.g., pour de la recherche d'information, effectuer de simples recherches de spécialisations et/ou généralisations par comparaisons de graphes est souvent suffisant. Ainsi, pour de la recherche d'information, il est intéressant de retourner la phrase "Les autruches ne volent pas" à la requête "Est-ce que les oiseaux volent ?" même si ni "Les oiseaux volent" ni sa négation ne sont des implications logiques de "Les autruches ne volent pas".
En conclusion, pour modéliser et partager des informations générales (e.g., des phrases en langage naturel) il vaut mieux utiliser une logique plus expressive que RDF+OWL pour éviter de ne pas pouvoir représenter ces informations (e.g., représenter "par définition, un oiseau vole" au lieu de "En France, en 2010, selon l'étude de Dr X, au moins 80% des oiseaux en bonne santé sont capable de voler".
Généralisation (abréviations en FL: "_↗", "_/^", "_/"); inverse: spécialisation (en FL: "\_"). `Xs has for generalization Xg' <=> [Xs generalization: Xg] <=> `Xs _/^ Xg' <=> `Xs _↗ Xg' <=> "Xs contient plus d'informations que Xg" `Xg has for specialization Xs' <=> [Xg specialization: Xs] <=> `Xg \_ Xs' <=> `Xs _↗ Xg' Dans ce cours, par défaut, les relations sont "strictes", i.e., elles n'incluent pas la notion de "or equal/equivalent" ("équivalent" entre "phrase|formule|RC" telle que définie en section 1.1.5, et "égal" entre d'autres "objets d'information" tel que défini en section 1.1.1. Pour avoir ce "or eq" ("or equal/equivalent"), il faut le spécifier explicitement, e.g., generalization_or_eq (en FL: "=_↗", "=_/^"), specialization_or_eq (en FL: "\_=").
Spécialisation depuis un type: relations subtype (en FL: "\.") et instance (en FL: "|.") ( l'inverse de subtype est supertype|subtypeOf ; en FL: "↗", "/^" ; avec "or eq:": "=↗", "=/^" ; l'inverse de instance est type|instanceOf ; en FL: "↑", "|^" ) En FL: [^t subtype: ^st] <=> [^t \. ^st] <=> [^st subtype of: ^t] <=> [^st ↗ ^t] <=> [ [^i instance of: ^st] => [^i instance of: ^t] ] <=> [ every ^st instance of: ^t ] Les relations "natural_subtype" (en FL: "\:") et "non-natural_subtype" (en FL: "\..") sont plus précises.
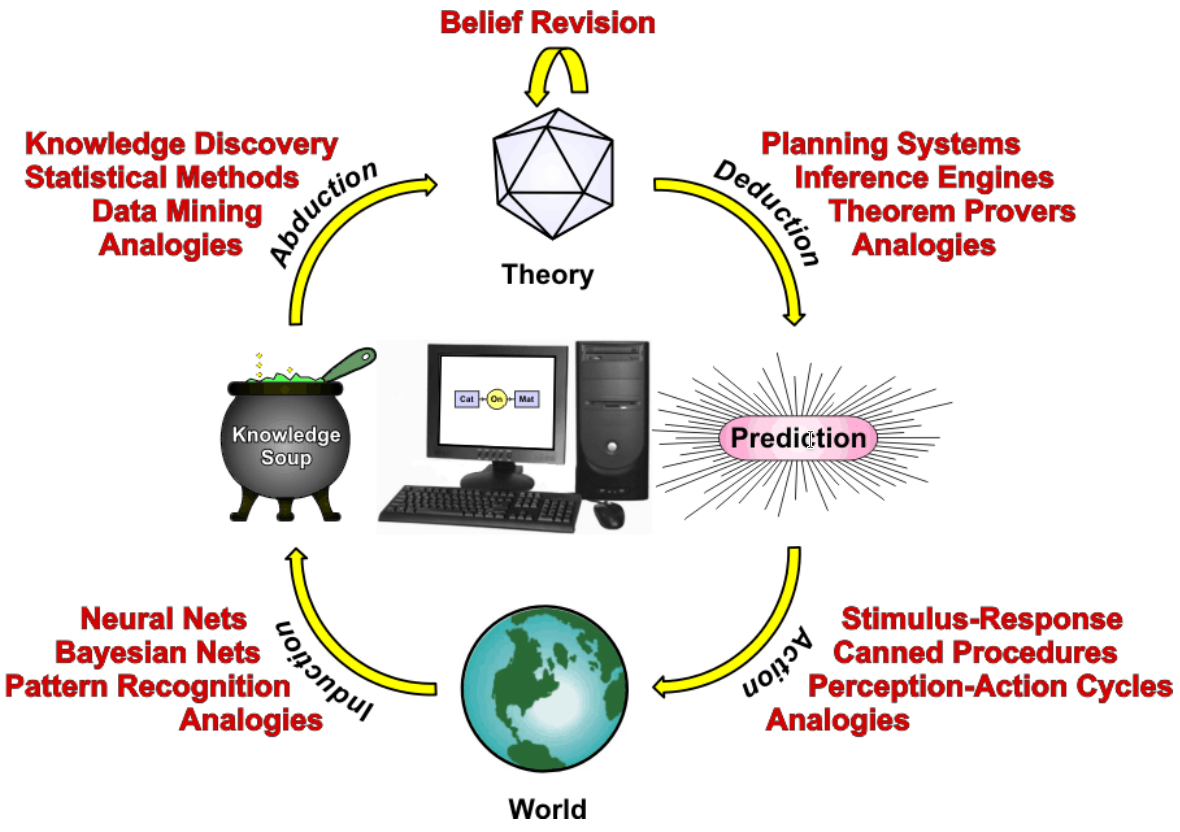
Inférence: méthode de raisonnement pour, à partir de connaissances (alors appelées "données" ou "faits" de l'inférence, qu'ils soient vérifiés ou non), générer une autre connaissance (alors appelée "résultat" de l'inférence). Lorsqu'une méthode n'est pas logique (et donc non sûre), son résultat doit être testée par rapport à des observations. Il existe quatre types principaux d'inférences: la déduction (seul type d'inférence logique), l'abduction, l'induction et l'analogie.
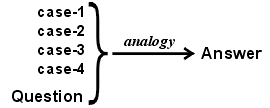
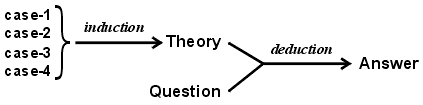
Dans son sens général,
l'argumentation
rassemble toutes les techniques utilisables pour convaincre.
Les
arguments utilisant la
déduction sont logiques, les autres sont fallacieux.
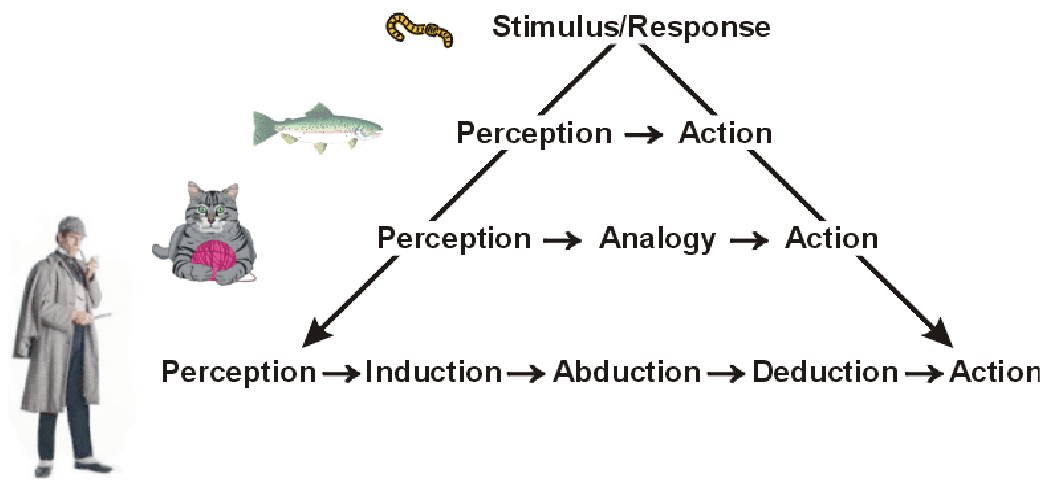
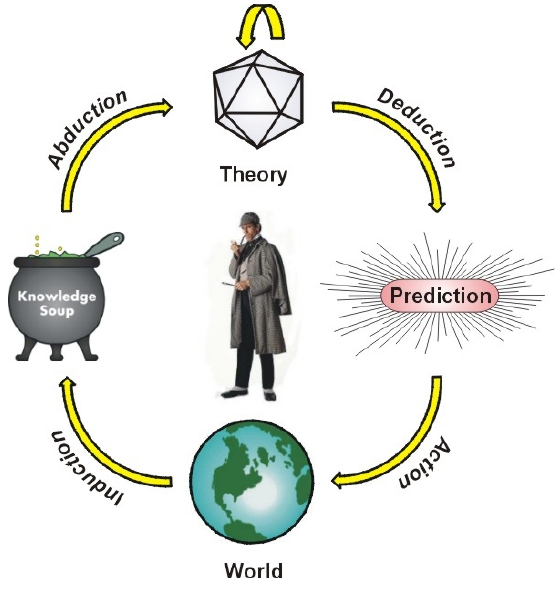
(les sources de ces images sont accessibles en cliquant sur elles)
Implication au sens large; abréviations en FL: "-::" (implication stricte), "=::" (non stricte)
Quelques autres opérateurs logiques (les exemples sont en FL à 1 détail près: pour plus de clarté, les variables x, y, z et r sont implicitement quantifiés universellement sans être préfixés par '^') : * and and{x,y,z} <=> [x ∧ y ∧ z] * or or{x,y,z} <=> [x ∨ y ∨ z] * not (abréviation en FL: "¬" or "!") - d'un type: le complément de ce type Nothing = ! Thing - d'une phrase|formule|RC [x ! r: y] <=> ! [x r: y] * equivalence (abréviation en FL: "<=>") [x <=> y] <=> [ [x => y] ∧ [x <= y] ] * non-equivalence (abréviation en FL: "!<=>") * equal (abréviation en FL: "=") cf. page suivante * different-from (abréviation en FL: "!=") [x != y] => [x !<=> y]
exclusion (abréviation en FL: "£" or "->!") * entre types (x et y: x =/^ !y): pas d'instances communes ni donc sous-types communs * entre phrases|formules|RCs (x et y): contradiction entre ces phrases (i.e. x => !y) ou, si ces phrases sont des croyances (donc de la forme [^believer1 believer of: ^x1] et [^believer2 believer of: ^y1] ), ^x1 => ! ^y1
member en FL: [ {1..* Thing x} ^collection ] <=> [^collection member: x] Être instance d'un type, c'est être membre de l'extension de ce type
part en FL: [ {1..* Thing} ^c1 part: {1..* Thing ^x2} ^c2 ] <=> [^c1 member: ^x2] L'extension du sous-type d'un type X fait partie de l'extension de X
correction cf. exemple en section 1.4.3
w@ ≡ w. ≡ 0 ≡ 002 ≡ 08 ≡ 02
@w@ ≡ .w. ≡ 1 ≡ 012 ≡ 18 ≡ *"1" ≡ IR
@@w@ ≡ ..w. ≡ 2 ≡ 102 ≡ 28 ≡ *"2" ≡ IIR
@@@w@ ≡ ...w. ≡ 3 ≡ 112 ≡ 38 ≡ *"3" ≡ IIIR
....w. ≡ 4 ≡ 1002 ≡ 48 ≡ *"4" ≡ IVR
.....w. ≡ 5 ≡ 1012 ≡ 58 ≡ *"5" ≡ VR
... ...w. ≡ ......w. ≡ 6 ≡ 1102 ≡ 68 ≡ *"6" ≡ VIR
. ... ...w. ≡ .......w. ≡ 7 ≡ 1112 ≡ 78 ≡ *"7" ≡ VIIR
.... ....w. ≡ ........w. ≡ 8 ≡ 10002 ≡ 108 ≡ *"8" ≡ VIIIR
.... ....w. ≡ .........w. ≡ 9 ≡ 10012 ≡ 118 ≡ *"9" ≡ IXR
..... .....w. ≡ ..........w. ≡ 10 ≡ 10102 ≡ 128 ≡ *"10" ≡ XR
. ..... .....w. ≡ ...........w. ≡ 11 ≡ 10102 ≡ 138 ≡ *"11" ≡ XIR
Afin de prouver sa compréhension/interprétation des symboles et notions de cet encart (ce message)
– et donc aussi une certaine intelligence de sa part –
un lecteur de ce message pourrait par exemple émettre le message suivant.12 ≡ .... .... ....w. ≡ 11002 ≡ 1'1002 ≡ 148 ≡ *"148" ≡ XIIRLes messages envoyés par le SETI à d'éventuels extraterrestres intelligents, dont le message d'Arecibo et le message de Dutil et Dumas (explication pointée par ce lien) envoyés en 1999 sont bien plus compliqués. Après avoir introduits d'autres notions mathématiques (e.g., addition, exposants, équations, ...), ces messages réfèrent|identifient des notions physiques (e.g., distance, mètre, mètre/secondes, accélération, ...) et/ou des éléments physiques (e.g., atomes, molécules, ...) via des rapports|équations supposé(e)s connus entre certaines de leurs propriétés physiques.
Entity £ Process Bird↗ ↖Counting //or: Flight Tweety↗
`no Bird can be agent of a Counting´ //false belief £ £ £ `at least 1 Bird ⇐ `at least 50% of Bird `each Clever Bird can be agent of can be agent of can be agent of a Counting´ a Counting´ a Counting´ ⇑ ⇖ ⇖ ⇗↙ `1 Bird `Tweety can be `each Bird can be agent of a Counting can be agent of that has for duration agent of a Counting´ at least 0.5 Hour´ a Counting´ ⇑//if Tweety still can ⇑↓ `Tweety has been agent of a Counting `each Bird|Bat can with duration at least 0.5 Hour´ be agent of a Counting´
Legend. "→": generalization (en FL: "_/^") that is not an implication, e.g. subtypeOf (en FL: "/^"), instanceOf; "⇒": implication_or_equivalence; "£": exclusion (ici: [x £ y] <=> [ [x ⇒ ¬y] ∨ [x =/^ ¬y] ] ) ; "can": is able to; every sentence is in FE; relation types are in italics; concept types begin by an uppercase; the authors of IDs, sentences and relations are not represented (unlike in next page); in FE, "each" (alias 100%) and "%" are for "observations" and hence imply "at least 1", whereas "any" is for a "definition" and hence does not imply "at least 1"; the distinction is important since observations may be false while definitions cannot (since agents can give any identifier they want to the types they create) and thus cannot be corrected or contradicted. "\_" est l'abréviation de la spécialisation en FL. Notons "\__" la spécialisation entre formules logiques "simples", i.e., entre formules existentielles conjonctives avec ou sans contextes négatifs, i.e., entre formules utilisant ∃ et/ou ∧ mais pas ¬, ∀, ni de quantificateurs numériques. On a : [A \__ B] => [ [A \_ B] ∧ [B => A] ] Ces différentes relations sont très utiles pour effectuer des requêtes sur la BC.
u1#`each Bird is agent of a Flight´ | \c=> _[u3] | ↘ u3#`at least 75% of Healthy Flying_bird can be agent of a Flight´ | ↑ |c=>_/^ _[u2] |c=> _[u3] ⇐ ... ↓ | u2#`each Bird can be agent of a Flight´
Legend.
"------(typeID) _[userID]----→": relation of type typeID, created by userID
"u1#...": u1 is the author of the prefixed statement;
"c=>_/^": correction and implication and semantic/structural generalization;
"c=>": correction and implication (no specialization/generalization);
"⇐": implication relation with destination on the left; "each": 100%
Thing := "anything that exists or that can be thought about", \. partition { (Situation := "anything "occuring" in a real/imaginary region of time&space", \. partition { (State = ^"Situation that is not a process") (Process = ^"situation "making a change", \. (Problem_solving_process :=> "e.g., software_lifecycle_process") ) } (Situation_playing_a_role :=> "e.g., outcome, accomplishment") ) (Entity := "thing that is not a situation -> that may "participate" to one", \. partition { (Spatial_entity \. partition { (Physical_entity \. entity_that_can_be_or_was_alive) (Spatial_non-physical_entity :=> "e.g., geometry_object") } (Spatial_object_playing_a_role := "e.g., place, physical_entity_part/substance") ) (Non-spatial_entity \. partition { (Non-spatial_entity_existentially_dependent_on_another_entity = ufo#Moment, \. partition { (ufo#Intrisic_Moment \. (ufo#Mode :=> "e.g.: John's desire, Intention, Perception, Symptom, Skill", = Characteristic_or_attribute_or_measure, \. partition { (Characteristic :=> "e.g., color, wavelength") (Attribute_or_measure :=> "e.g., red, '620 to 740 nm'") } (ufo#Externaly_Dependent_Mode part of: 1 Relator, ufo#externaly_dependent_on: 1..* Entity ) ) ) (ufo#Relator :=> "e.g., Marriage, Enrollment, Employment, Mandate") } ) (Non-spatial_entity_existentially_independent = Non-spatial_substantial, \. partition { (Temporal_entity := "e.g., date, duration") (Non-spatial_non-temporal_substantial \. partition { (Description_content/instrument/support \. (Description :=> "e.g., Type, proposition") (Description_instrument :=> "e.g., language") (Description_support :=> "e.g., file") ) (Non-spatial_non-temporal_non-chrc/meas/desc_substantial :=> "e.g., justice" ) } ) } ) } ) } (Entity_playing_a_role :=> "e.g., owner, agent") } (Thing_playing_a_role :=> "e.g., creation, part");
------------------------0..*--> |______________________________ Spatial_entity Temporal_entity <--1..*--------------------------- (relation_to_another_spatial_entity) ^ ^ | \0..* 1..*/ | \ / | (relation_from_process_to_spatial_entity \ /(relation_from_process_to_temporal_entity | \. from_place place \ / \. since_time time duration to_place via_places) \ / until_time) | \ / | \ / (relation_from_state_to_temporal_entity)| ---0..*--> Process_attribute \ / | |____________________________________________ | | --------------------------------1..*--> Event | (relation_from_process_to_process_attribute \ | | /(relation_from_process_to_event | \. manner speed) \ | | / \. triggering_event ending_event) | \ | | / | \| |/ | 1..* State <--------------------------------- Process ---------------------------------------> 1..* State | (predecessor_state / | | \ (successor_state | | \. beginning_state / | | \ \. end_state postcondition | | precondition cause) / | | \ consequence purpose) | |(part) | | | | (part)| | | | | | | | (relation_to_process_participant | | | |(relation_to_created-or-modified_participant | | \. (relation_to_used_object | | | | \. (relation_to_created-or-modified_object | | alias: object, | | | | \. input-output_object generated_object | | \. input_object parameter | | | | deleted_object) | | material instrument) | | | | (relation_to_modified_agent | | (relation_to_participating_agent| | | | \. patient experiencer recipient) ) | | \. agent initiator) ) | | | | | v v | | v v 1..* State <----------------- 1..* participant | | 0..* participant -----------------------> 1..* State (state) / \ (state) / \ (relation_to_description / \(relation_to_another_process \. description) / \ \. specializing_process generalizing_process | | sub-process method embedding_process) | | 0..*| |0..* ---------------------------0..*--> v v |______________________________ Description_... Process (relation_to_another_description | | \ \. generalizing-description | | \ sub-description correction) | | ------------------------0..*--> Description_medium | | (description_medium) | | Agent <--1..*--------------------------/ \----------------------------0..*--> Description_container (description_believer) (description_container)
Note: les graphes PERT
relient des processus par des relations next_process
qui peuvent se définir ainsi : next_process (Process ?p1, Process ?p1) := [?p1 successor_state: (a State predecessor_state of: ?p2)].
Les réseaux de Petri sont plus précis : les
processus y sont reliés via leurs états d'entrée et leurs états de sortie ; ces réseaux utilisent
donc des relations de type successor_state et/ou predecessor_state mais implicitement
(i.e., comme ce sont les seuls types de
relations autorisés dans ces réseaux, ces types n'apparaissent pas).
Cliquez ici pour quelques exemples de réseaux de Petri dans une
notation proche de FL mais dédiée à ces
graphes (→ les types de relations sont implicites dans cette notation).
Connaissance tacite: connaissance qui n'est pas explicite, i.e., qui n'a pas été décrite précisément dans un document ou un SGBC. Certaines connaissances, comme les savoir-faire et la reconnaissance de situations ou d'objets (visages, écriture, ...), sont difficiles à décrire ou définir précisément et donc à représenter. En psychologie cognitive, cette distinction se retrouve dans la distintion entre mémoire procédurale et mémoire déclarative.
"Gestion des connaissances" (au sens commun / des industriels)
[knowledge management]:
ensemble des techniques permettant de collecter/extraire, analyser, organiser
et partager des informations, le plus souvent à l'intérieur
d'une organisation, e.g. les connaissances importantes d'un employé
(carnet d'adresses, trucs/expertise, etc.)
avant qu'il ne parte à la retraite.
Ces informations sont généralement stockées sous la forme de
documents informels, très rarement via des représentations de
connaissances, du moins jusqu'à présent.
Un outil permettant une telle gestion est un
système de gestion de connaissances (SGC)
[knowledge management system (KMS)].
"Gestion|ingénierie des connaissances" (au sens des universitaires)
[knowledge engineering]:
ensemble des techniques permettant de collecter/extraire, représenter, organiser et
de partager des représentations de connaissances (cf. page suivante).
Un système de gestion de BC (SGBC) [KB management system (KBMS)] est un
des outils permettant une telle gestion. D'autres outils sont ceux de
collection/extraction et analyse de connaissances qui aident à créer
un SGBC.
Système à base de connaissances (SBC): tout outil exploitant des représentations de connaissances par exemple pour résoudre certains problèmes. Techniquement, un SGBC est aussi un SBC mais est rarement classé en tant que tel. Les systèmes experts sont des SBCs mais ne sont pas forcément basés sur des "connaissances profondes" (représentations détaillées de connaissances nécessaires à un raisonnement).
Gestion de contenu [Enterprise Content Management (ECM)] : prendre en compte sous forme électronique des informations qui ne sont pas structurées, comme les documents électroniques, par opposition à celles déjà structurées dans les SGBDs. Ceci peut être vu comme un cas particulier de "gestion des connaissances, au sens des industriels". De plus, si des métadonnées "précises" sont utilisées pour indexer les documents, "gestion de contenu" implique aussi des tâches d'ingénierie des connaissances".
Le mot "contenu" a donc divers sens contradictoires. Dans "gestion de contenu", ce mot réfère à des données non structurées. Dans "recherche de documents/informations par le contenu", il réfère à la sémantique des informations, par opposition à leur structure ou leurs aspects lexicaux (orthographe, ...). Dans "recherche d'images par le contenu", il réfère soit à la sémantique de l'image (les choses qu'elle contient et leur relations spatiales), soit à des caractéristiques visuelles de l'image comme les textures, couleurs et formes qu'elle contient.
Rappel : dans ce cours, ailleurs que ci-dessus dans cette page, les sens universitaires sont utilisés : "connaissance" réfère à "représentations de connaissances (RCs), et "BC" réfère donc à "base de RCs".
L'utilisation de BCs/RCs rend non pertinent l'utilisation d'une architecture de données ou basée sur des données.
WWW (Web)
[World Wide Web]: (système
hypermédia sur l')ensemble des
ressources (documents ou élément de documents,
bases de données/connaissances, ...) accessibles via internet.
À l'origine, techniquement, le Web n'est que l'implémentation
d'un système hypertexte très simple (HTTP + HTML + navigateur Web) sur
Internet (i.e., via
TCP et
DNS).
Web 2.0: mot "fourre-tout" (utilisé à partir de 2001 mais enfin passé de mode) désignant
Par opposition à la partie du Web 2.0 du Web, le reste est un "Web de documents statiques (i.e., non dynamiques)".
Web 3.0: mot "fourre-tout" (utilisé à partir de 2009) désignant les futures applications, combinaisons et évolutions des technologies récentes et en particulier celles liées
"Web sémantique" [Semantic Web]: mot (surtout utilisé à partir de 1996, soit 4 ans après la naissance officielle du Web) désignant
Par opposition à la partie Web sémantique du Web, le reste est un "Web peu/non compréhensible par les machines".
Définitions plus précises (et équivalentes entre elles)
pour le 1er sens de "Web Sémantique" :
- sous-ensemble des informations du Web dont le sens a été au moins
partiellement défini
dans des formats standards (et donc que des logiciels peuvent utiliser pour faire
certaines déductions logiques pour de la
résolution de problèmes ou être plus (inter-)opérables).
- connaissances du Web exprimées dans des langages standards et
informations indexées par ces connaissances ou méta-données.
QW P3wooclap (questions sur le Web de données)
QW P3wooclap (questions sur la recherche d'informations) :
cf. sections 1.2 et 1.3.1.
Tous les moteurs d'inférences proposent un moyen de savoir si
une (phrase "proche" d'une) phrase particulière existe dans une BC,
ou peut être déduite de cette BC,
ou si sa négation ne peut être déduite de cette BC.
Pour permettre de spécifier de telles requêtes, divers opérateurs de recherche
peuvent donc être proposés; ils prennent en paramètre une
"phrase requête".
Le langage de requête proposé peut ne contenir qu'un opérateur (qui peut
par exemple être noté "?" ou être implicite) mais peut proposer des moyens de
combiner diverses requêtes ou commandes.
Généralement, le langage de requêtes proposé est une extension du langage
proposé pour affirmer des phrases.
Il est généralement plus facile pour un moteur d'inférences de gérer de
manière exacte et complète des requêtes exprimées avec une notation
pour une logique du 1er ordre que des
affirmations effectuées avec une notation pour une logique du 1er ordre.
Dans WebKB, le langage de requêtes/commandes est appelé FC (For Control).
Il propose divers opérateurs qui peuvent utiliser des phrases requêtes écrites
dans divers LRCs. Toutes les requêtes peuvent être écrites avec
l'opérateur "?", les autres opérateurs sont des abréviations.
Ci-dessous, quelques exemples commentés.
Lorsque non-explicitée, la notation ici utilisée pour les phrases requêtes est
FL.
Revoir la section 1.4.2 pour la différence entre "=> et "_/^".
? [a cat part: a paw] //-> réseau (ici, une hiérarchie de géneralisation/implication // des phrases de la BC qui impliquent le graphe requête) //Pas de réponse -> faux ?? [a cat part: a paw] //renvoie True s'il y a au moins une réponse, False sinon ? [a cat part: a paw] <= ?s //-> idem ?s [a cat part: a paw] <= ?s //-> liste (et non réseau) des phrases impliquant [...] ? [a cat part .^2..4: a paw] //-> chaîne de 2 à 4 relations "part" (avec leurs contextes // si elles en ont) reliant cat à "paw" ? [a cat part .^1..*: a paw] //-> chaîne d'au moins une relation "part" reliant cat à "paw" ? [a cat part .^+ : a paw] //idem (note: même si ceci est sans réponse, [a cat part: a paw] // peut être vrai via d'autres définitions/règles/relations que des relations "part"; // en effet, le `^+´ étant une expression régulière sur des chemins de relations, // la recherche de réponse se fait par comparaison de graphes/chemins et non via // un mécanisme complet de déduction logique comme avec "<=") ? [a cat part: a paw] <= .^1 ?s //-> réseau des phrases directement et explicitement impliquantes ? [a cat part: a paw] => .^1 ?s //-> 1 relation "=>" directe et explicite de [...] à ?s ? [a cat part: a paw] =_/^ .^1 ?s //-> 1 specialisation directe et explicite de ?s à [...] ? [a cat part: a paw] \_ .^1 ?s //-> réseau des phrases directement et explicitement spécialisantes ? [a cat part: ?x] //-> réseau des phrases impliquant que cat a des sous-parties ?x [a cat part: ?x] //-> objets sous-parties de cat ? [cat \. .^1 ?x] //-> hiérarchie des sous-types directs de cat ? cat \. .^1 ?x //idem (car en FL, les [] de premier niveau sont optionnels) ? `cat has for direct subtype ?´ //idem avec la notation FE pour la phrase requête ? [cat /^ ?x, \. ?y] //-> hiérarchie des super-types et sous-types de cat ?x,y [cat /^ ?x, \. ?y] //-> liste des super-types et sous-types, préfixés par "?x=" et "?y=" ? [cat !exclusion: ?x] //-> réseau des (phrases montrant les) IDs non exclusifs à cat ?s [cat part: 4 leg] !exclusion: ?s //-> liste des phrases non exclusives à [...] ? [a cat (relation: a thing)^1..3 emplacement: fr#"France"] //-> chaîne de // 1 à 3 relations entre une instance de cat et quelque chose ayant pour // emplacement quelque chose qui en Français est appelé "France" ?3 [a cat part: ?x] //renvoie au maximum 3 graphes réponses ?3:x [a cat part: ?x] //renvoie au maximum 3 valeurs pour ?x ??:x [a cat part: ?x] //renvoie True si ?x existe et si son quantificateur est différent de 0|no ?2..4:x [a cat part: ?x] //renvoie au maximum 4 valeurs pour ?x ou aucune s'il n'y en a pas au moins 2 ??3:x [a cat part: ?x] //renvoie True s'il y a au moins 3 valeurs pour ?x, False sinon
Note: ci-dessus, les expressions du type "quelles phrases de la BC impliquent ..." réfère
à des phrases "minimales" (car sinon, la BC pouvant
elle-même être considérée comme une (grosse) phrase,
la réponse serait la BC entière).
Ici, "minimale" signifie "qui serait - ou pourrait
être - faux si un élément était omis".
Une phrase minimale inclut donc ses
phrases contextualisantes. Par exemple,
si la requête est : ? [a animal part: 4 leg] \. .^1 ?s
et si la BC contient la phrase suivante :
[ [2 cat part: 4 ^(leg color: a yellow), owner: Tom]
time: 21/12/2020]
alors une réponse est :
[ [2 cat part: 4 ^(leg color: a yellow)] time: 21/12/2020]
La précision "owner: Tom" n'a pas à être incluse dans une réponse
minimale, par contre
il vaut mieux inclure précision "color: a yellow" car
TD 4 + cf. TP 3 et solution TD 3.
QWs "TD3wooclapUnicode + CM4" (6/7, 8/9, 10/11/12)
Étudiez
Cf. TD/TP 4.
Cf. TP 5.
Cerveau:
environ 1012 neurones (~ portes logiques complexes pouvant "commuter"
des centaines de fois par seconde, au mieux).
Chaque neurone peut être connecté à 104 neurones; différentes zones spécialisées (vue, ouïe, ...).
Énorme redondance/distribution de l'information.
Le cerveau a un fonctionnement parallèle et statistique -> c'est une machine non "programmable" mais,
via son câblage (ses connections), il peut effectuer/découvrir/reconnaître des associations entre
certaines informations (images, sons, concepts, ...) et peut ainsi apprendre de nouvelles associations,
i.e., de nouvelles (combinaisons de) connections.
Ainsi, le cerveau est très efficace en reconnaissance (d'images, de sons, ...) mais
très inefficace en application de procédures/règles et, de plus, le cerveau commet beaucoup
d'erreurs arithmétiques/logiques/...
Ordinateur classique: 1 ou plusieurs microprocesseurs, chacun composé de millions/milliards de
transistors (~ portes logiques simples pouvant commuter des milliards de fois par seconde).
Il y a peu de redondance (la perte ou modification d'un seul bit peut être fatale).
Un ordinateur classique a un fonctionnement procédural (et donc essentiellement séquentiel)
-> il n'apprend que s'il applique un programme d'apprentissage;
-> peu efficace en reconnaissance (d'image, de son, ...); très efficace en application de procédures/règles;
-> il ne commet pas d'erreurs d'application de programme (mais des bits peuvent se perdre ou
le programme peut avoir des erreurs).
Réseau (classique) de neurones (artificiels): quelques dizaines/.../milliers de neurones artificiels
(simplification de neurones naturels), chacun connecté à une ou plusieurs dizaines de neurones
(cf. ces progrès matériels en 2022).
Un tel réseau a un fonctionnement parallèle et statistique -> utile pour la reconnaissance (d'images, sons, ...)
-> mêmes problèmes que pour le cerveau.
Modèle de language
de grande taille [Large language Models (LLMs)] :
modèle statistique
(proche de ceux de
l'Apprentissage Profond
[Deep Learning] et donc des réseaux neuronaux
modélisant la distribution statistique de séquences de mots/lettres/... et donc,
pour une séquence donnée, stockant différente suites à cette séquence et leurs
probabilités (cf. théorème de Bayes)
majoritairement utilisé pour le
traitement automatique des langues ou la
reconnaissance automatique de la parole)
contenant/modélisant des millions/milliards de "paramètres" (critères/charactéristiques utilisés pour
représenter puis analyser une séquence donnée et donc reconnaître
la meilleure suite à une séquence donnée), e.g.:
Ces modèles|réseaux statistiques ne stockent et
n'exploitent pas des représentations de connaissances.
Ils sont donc des réseaux de données, ne "représentent" pas (explicitement, en logique) le monde réel,
ne sont pas capables (au sens classique) d'inférences logiques (ils ne font que de la "reconnaissance"),
et
ne sont donc pas capable "d'expliquer au sens classique" leurs résultats.
Toutefois, ils (au moins GPT) sont capables d'effectuer des tâches
i) dont le résultat semble correct ou cohérent, et
ii) qui, pour un tel résultat, requièrent usuellement un raisonnement logique ou une compréhension
(et la connaissance de certaines techniques),
e.g., répondre à des questions d'une manière qui semble cohérente, calculer, créer des programmes,
résumer un texte, traduire ou compléter des phrases, répondre correctement à des questions, etc.
En réalité, ces outils ne font que simuler des déductions via
un raisonnement "statistique" proche de l'induction et de l'abduction (cf.
types d'inférences en section 1.4).
Ces outils peuvent donc être utilisées comme des guides (des générateurs de suggestions) mais
leur faire confiance est dangereux,
dans tous les domaines (e.g.,
littéraire ou mathématiques,
comme en programmation: 1,
...),
bien plus qu'à des programmes classiques bien débogués ou
dont le fonctionnement correct a été prouvé formellement). E.g.,
actuellement la plupart de ces
outils statistiques ignorent ou ne traitent pas correctement les
négations dans leurs
textes sources (ils peuvent donc conseiller de faire le contraire de ce qu'il est souhaitable de faire).
Étant "statistiques", ils imitent aussi de mauvaises habitudes [1, 2, 3] et ont des
"hallucinations".
Il y a différentes façons de combiner des modèles|réseaux statistiques avec des outils classiques
[1,
1+,
2,
...].
D'autres recherches travaillent directement sur les réseaux neuronaux pour améliorer leurs capacités de
raisonnement [1, 2],
d'explication [1]
ou pour savoir quelles notions linguistiques ils stockent
[1,
2].
About "Junior Software Engineers":
List of Prefix Examples For Common Types. Below, various prefixes are proposed for various types of objects and these types are organized into an indented list that show their subtype relations. When type names from Javascript (JS), C or C++ could be reused below, they are: they are within single quotes ('...'), JS/C++ class names have an uppercase initial, C type names have a lowercase initial (except for 'FILE'). The other type names are whithin double quotes ("..."). The type names in bold characters are the JS types reused in JSON and JSON-LD. Prefixes for the most precise types should be used (hence, for example, the prefix "num" should not be used if the prefix "int" can be used).
"Anything" (any information object): "x", "e","elem"(collection item) "PrimitiveObject" (object of a basic/built-in data type): "builtin" 'Symbol': "symbol", "symb" "type" (type) "PrimitiveValue" (literal or not, e.g. a Primitive in JS, typically a Number; in JS, null is also considered primitive): "v", "val", "value" "NonPrimitiveObject" (object of composite type or abstract data type, e.g. a "JS Object"): "o", "obj" //immutability (if not the default option) may also be specified (e.g. "oim") and used // since it allows safer, simpler and sometimes quicker functions; see also this in C++ 'union': "u" //except for "uc" ("unsigned char") 'Function': "fct", "f" //see Box 1 (above) 'FILE': "fi", "fp" (file pointer, "pf" is also ok) //but "ifd": int "file descriptor"; see std::filesystem too) "ReferenceObject" "AtomicReference": "p" (object that is an in-memory pointer or would be if translated in C++), "rp" (object that is a C++ reference or would be if translated in C++), "rpc" (const "rp", i.e. the value cannot change), "rpco" (const "rp" on an object) "IdReferenceObj" (-> id/key or mainly including that): "r", ro", "rid" //but "StringIdForAnObject": "sid" "Iterator" (function/pointer/... to traverse a collection, e.g. std::iterator): "iter" "Cursor" (to traverse/point to an object/collection, esp. in a DB): "cr"(read cursor), "cu"(update cursor) "Conteneur" (alias, "Collection_ADT"): "coll", "collv" (for a "view": collection of items/references, each removed when what is pointed to is removed (e.g. garbage collected), e.g. std::span)
"PrimitiveValue" (literal or not, e.g. a Primitive in JS, typically a Number): "v", "val", "value" 'Number': "nr" //but "n", "nb" and "num" are for Naturals; see below "nru" (unsigned, i.e. >=0), "nrp" ('p': strictly positive, i.e., >0), "nr32"|"nr4b"|"fl" ('float': floating-point number of at least 32 bits (3 bytes)) "nr64"|"nr8b"|"d" ('double': floating-point number of at least 64 bits (8 bytes)) "dl" ('long double': generally 10 to 12 bytes; see en.cppreference.com/w/cpp/language/types) "n64u" (unsigned n64), "flp" (positive float) 'int': "zi" ('z' par référence à l'ensemble de entiers relatifs Z 16 or 32 bits on a 32-bit system), "zis" ('short int': 16 bits), "zil" ('long int': n bits on a n-bit system) "zill" ('long long int': 64 bits on a 32/64-bit system) "zib" (JS BigInt: used in JS to represent arbitrary large integer, those ≥ 253) "enum": "enum" (e.g. std::byte) "int>=-1": "i" (to follow by a number, do not use "j", "k" ), "index", "lastIndex", "fromIndex", "toIndex" (esp. for Get-from/Generate-from fcts) 'uint' ("natural"): "n", "nb", "num", "ui", "uint" 'size-t' ("usize"): "size", "lng", "length", "uIndex", "uindex", "depth" //note: these prefixes may be preceded by "min" or "max" "nb16"|"nb2b" (natural on 2 bytes), "nb32"|"nb4b" (natural on 4 bytes) "natural>0": "np", "ip" (cf. prefixes 'p' and 'u' and 'nr' above) 'byte' ([0 to 255]): "uc", "ui1b" //since "cu" is for "update cursor" (see below) "Truth-value/Boolean-like" ('bool', O12, O123): "b", "b012" "b0123", "has", "is", "are", "may", "no", "do", "with", "for", "in", "equal" 'char': "c", "char", "cz" ([-127 to 127]), "uc" ([0 to 255]), "cs1" (string of length 1, as in JS)
QWs "Listez les 8 noms ..." + "Le kibi (Ki) ..."
"Collection_ADT"|"Conteneur": "coll", "collv" (for a "view": collection of items/references, each removed when what is pointed to is removed (e.g. garbage collected), e.g. std::span) "Sequence": "seq", "stack" (std::stack), "queue" (std::queue), "queueWpriority" (std::priority_queue") "List" (non-mumericaly indexed sequence): "list", "lst", "li" "SingleLinkedList" (forward-only, e.g. std::forward_list): "lif" "DoubleLinkedList" (forward+backward, e.g. std::list): "lifb", "lifbqueue" (std::deque) 'Array' (-> numerically indexed): "a", "ar", "arr", "subArr", "table" "as" (atatic: fixed-size), "ad" (dynamic, hence a "vector") "ab" (array/view for a blob, i.e. for a binary large object) "aspan" (span: view on an interval on another array) "ArrayOfHeterogeneousValues" "Tuple" (fixed-size, e.g. std::tuple, std::pair): "tup", "tuple", "pair", "triple" "ArrayOfHomogeneousValues" (e.g. std:array, std::vector) "NullTerminatedArray": "a0" ("sc" or "sa" if C-like string) "StringOrCharPointer": "s"/"str" (<=> "sc" in a C program, "dstr"/"string" in a JS program), ("1st"/"2nd"/...)("sub")("str"/"name"/"word"/"w"/"text"/"token"), "to"("Locale")("String"/"Print") (for Get-from/Generate-from fcts) "Cstring": "sc" (non-allocated C-like string pointer), "sa" (allocated C-like char array) 'String' (with a size/length attribute): "ds", "dstr", "string" "StringView" (e.g. std::string_view): "strv" "KeyedCollection" "Multimap" (associative array that may store the same key several times, e.g. C++ std::map): "mapm" 'Map' (e.g. C++ std::map): "aa", "aah" (map based on an hash-table) "MapView" (or 'WeakMap') : "aav" (stores 'key/referenceToValue' items; see "view" above) "Multiset" ("Bag", e.g. C++ std::multiset): "setm", "bag", "bagh" (bag based on an hash-table) 'Set' (e.g. C++ std::set): "set", "seth" (set based on an hash-table) "SetView" (or 'WeakSet'): "setv" (stores 'referenceToValue's; see "view" above) "Graph": "graph" "Tree" (connected acyclic graph; generally "undirected" in math and directed in data structures): "tree" "Heap" (std:make_heap): "heap"
Cf. "Some Programming Best Practices Or Conventions" -
"PP_2.3.7: using a "method naming convention" ... (dont
la table d'exemples donnée !) et
PP_2.3.8 pour les fonctions qui ne sont pas des méthodes.
Exemple de (classification de) fonctions utiles.
Note sur Haskell, la programmation fonctionnelle et l'erreur de ne pas essayer de (et donc "se focaliser à") comprendre des paradigmes auxquels on n'est pas habitués.
Linux uses C, not C++ (which has object-oriented abstractions),
to ensure performance in some critical cases, but:
Autres pages intéressantes et liées à ce paragraphe
(il n'est pas obligatoire de lire ces autres pages) :
1 (itérateurs, ...),
2 (optimisation par les maths),
3 (un exemple de commentaire de Linus sur une possible addition à Linux)
Contrairement à la plupart des autres langages (dont Java),
C/C++ ne cache pas la notion de pointeurs
(ce qui a des avantages comme l'illustre l'idée basique référée dans le précédent paragraphe) et
laisse le programmeur gérer la mémoire :
Autres pages intéressantes et liées à ces paragraphes
(il n'est pas obligatoire de lire ces autres pages) :
1 (about speed),
2 and
3 (about C),
4 (about Go),
5 (about Higher-Order Perl).
Ce cours devrait aussi vous permettre de comprendre pourquoi les idées du
livre The Mythical Man-Month (1975-1995)
ne sont vraies que si l'on ignore une
approche importante (qui n'était pas réalisable en 1975 mais qui peut être utilisée maintenant).
Quelle est cette approche ?
Autres pages intéressantes (il n'est pas obligatoire de lire ces autres pages) :
- mauvais codes, erreurs dues à l'encodage, ... : [1]
- langages de programmation/requêtes les plus utilisés
221 points de code (cf. Wikipedia :
"code point",
"code unit",
"caractère abstrait",
par opposition à "glyphe", et
leurs rationale)
via
24+1 [0-1016]
"plans"
de 216 [0-FFFF16] codes), e.g. U+00C7 pour 'Ç'
("\u00C7" en C et JS en HTML: "Ç", "Ç" ou "Ç"), donc
plus qu'assez pour pour chaque caractère de chaque langue du monde.
Adopté par les standards récents et tous les systèmes d'exploitation.
Quelques sous-catégories de UNICODE :
Cette section 2.2 sera à utiliser dans votre
TD "RC sur l'encodage des caractères".
Vous devez bien-sûr préparer ce TD.
Ce sera très probablement vérifié/évalué à son début via des questions Moodle/Wooclap.
Voir aussi POWDER
(Protocol for Web Description Resources).
Pour définir des liens hypertextes en XML (plutôt qu'en HTML):
Cf. TP 5.
Différentes phrases représentant la même chose :
En: Each green mouse is (agent of a) dancing. //"each" -> this is an observation, hence at least one green_mouse exists // -> instead of: ∀?m green-mouse(?m) => ( ∃?d dancing(?d) ∧ agent(?d,?m) ) // the simpler following representation in PL can be given PL: ∀?m ∃?d green-mouse(?m) ∧ dancing(?d) ∧ agent(?d,?m) FL-DF: each green_mouse --agent of--> a dancing //only if "each" has priority over "a" FL-DF: green_mouse --agent of _[each->a]--> dancing FLc: green_mouse agent of _[each->a]: dancing; FLc: green_mouse agent of: dancing __[each->a]; FLnc: each green_mouse agent of: a dancing //all the above FL-DF and FL phrases should be read in the same way: // each green mouse is agent of a dancing
Les phrases ci-dessous sont syntaxiquement correctes mais
ne représentent pas la même chose que ci-dessus.
En: There is a dancing to which each green_mouse participate. En: There is a dancing that has for agent each green_mouse. PL: ∃?d ∀?m dancing(?d) ∧ green-mouse(?m) ∧ agent(?d,?m) FL-DF: dancing --agent _[a->each]--> green_mouse FL-DF: green_mouse <--agent _[each<-a]-- dancing FLnc: a dancing agent: each green_mouse //these last 5 FL-DF and FL phrases can/should be read in the same way: // (there is) a dancing that has for agent each green_mouse En: each mouse is dancing and is green PL: ∀?m ∃?g ∃?d mouse(?m) ∧ dancing(?d) ∧ green(?g) ∧ agent(?d,?m) ∧ color(?m,?g) FL-DF: mouse --agent of _[each->a]--> dancing //graph unconnected to the next one: mouse --color _[each->a]--> green FL-DF: dancing <--agent of _[a<-each]-- mouse --color _[each->a]--> green FL-DF: dancing <--agent of _[a<-each ?m1]-- mouse --color _[each ?m2->a]--> green FL-DF: dancing <--agent of _[a<-each ?m]-- mouse --color _[each ?m->a]--> green FLnc: each mouse agent of: a dancing, color: a green //these last 5 FL-DF and FL phrases should be read in the same way: // each mouse is agent of a dancing and has for color a green En: each mouse that dances is green PL: ∀?m ( (mouse(?m) ∧ ∃?d dancing(?d) ∧ agent(?d,?m)) => (∃?g green(?g) ∧ color(?m,?g)) ) //PL: ∀?m ( dancing_mouse(?m) ∧ (∃?g green(?g) ∧ color(?m,?g)) ) FL-DF: dancing_mouse --type _[any ?dm ^-> .]--> mouse | |---agent of _[?dm ^-> a]--> dancing //^dm -> dancing_mouse |---color _[each -> a]--> green FL-DF: mouse --agent of _[any ^dm ^-> a]--> dancing //^dm -> dancing_mouse |---color _[each ^dm -> a]--> green //each ^dm is green FLnc: each ^(mouse agent of: a dancing) color: a green //these last 3 FL-DF and FL phrases can be read in the same way: // each mouse that is agent of a dancing has for color a green //the FL-DF phrases can also be read: // each dancing_mouse -- defined as a mouse that is agent of a dancing -- // has for color a green
Différentes phrases représentant la même chose :
En: The cat Tom and at least 2 mice are dancing together. Each green mouse is (constantly) dancing. PL: //with "at least 1 mouse": ∃?d ∃?m dancing(?d) ∧ mouse(?m) ∧ cat(Tom) ∧ agent(?d,Tom) ∧ agent(?d,?m) ∀?m ∃?d green-mouse(?m) ∧ dancing(?d) ∧ agent(?d,?m) FL-DF: dancing <--agent of _[. -> a ?d]-- Tom <--instance-- cat |---agent _[?d -> 2..*]--> mouse |---agent _[a <- each]--> green_mouse --type _[any ?gm ^-> .]--> mouse |---color _[?gm ^-> a]--> green FL-DF: dancing --agent _[a ?d <- 1]--> Tom <--instance-- cat |---agent _[?d <- 2..*]--> mouse |---agent _[a <- each ^gm]--> mouse --color _[any ^gm ^-> a]--> green FL-DF: dancing --agent _[a ?d <- .]--> the cat Tom |---agent _[?d <- 2..*] _[a <- each ^gm]--> mouse --color _[any ^gm ^-> a]--> green FL-DF: 2..* mouse <--agent-- a dancing --agent--> the cat Tom green <--color _[a <-^ any ^gm]-- mouse <--agent _[each ^gm -> a]-- dancing FLc: dancing agent _[a ?d -> .]: (Tom instance of: cat), agent _[?d -> 2..*]: mouse, //or: _[?d <- 2..*] agent _[a <- each]: (green_mouse = ^(mouse color: a green)); FLc: dancing agent: the cat Tom __[a ?d -> .], agent: mouse __[?d<-2..*], agent: ^(mouse color: a green) __[a <- each]; FLnc: the cat Tom agent of: (a dancing agent: 2..* mouse); each ^(mouse color: a green) agent of: a dancing;
Ci-après, 3 exemples de "phrases affirmées" équivalentes, en
En [English], en PL (logique des prédicats en notation de Peano) et
dans les LRCs
CGLF (Conceptual Graph Linear Form), FE (Formalized English),
FCG (Frame/For Conceptual Graph), FL (For Links),
N3 (Notation 3),
KIF (Knowledge Interchange Format) et R+O/X (RDF+OWL linéarisé avec XML).
Ces exemples permettent d'illustrer et d'expliquer oralement l'usage de
quantificateurs et de définitions,
ainsi que plusieurs notions liées aux "relations sémantiques
(entre "noeuds conceptuels/sémantiques").
La notion de "relation sémantique" est précisée plus tard.
Les parties en italique sont optionelles (elles ne sont utilisées que pour la lisibilité).
Également pour une question de lisibilité, les sources des IDs et des
phrases ne sont pas précisées
sauf pour l'ID pm#blue_man et les IDs venant de OWL ou de RDF.
1) En : Tom -- who is a man -- owns a red hat and a bird. PL : ∃?h hat(?h) ∧ ∃?r red(?r) ∧ ∃?b bird(?b) ∧ man(Tom) ∧ owner(?h,Tom) ∧ color(?h,?r) ∧ owner(?b,Tom). CGLF: [man: Tom]- { <-(owner)<-[hat: *]->(color)->[red: *]; <-(owner)<-[bird] }. FCG: [the man Tom, owner of: (a hat, color: a red), is owner of: a bird]; FCG: [Tom, type: man, owner of: (a hat, color: a red) (at least 1 bird)]; FE : The man Tom is owner of a hat with color a red, and is owner of a bird. FE : The man Tom is owner of a hat that has for color a red, and is owner of a bird. FLnc: Tom type: man, owner of: a ^(hat color: a red) a bird; N3 : [a hat; color [a red]] owner [Tom a man; owner_of [a bird]]. N3 : a hat; color [a red]; owner [Tom a man; owner_of [a bird]]. N3 : [:h rdf:type hat] color [a red]; owner [Tom a man; owner_of [a bird]]. KIF: (exists ((?h hat)(?r red)(?b bird)) (and (type Tom man) (owner ?h Tom) (color ?h ?r) (owner ?b Tom))) R+O/X: <hat> <color><red/></color> <owner> <man rdf:ID="Tom"><owner_of><bird/></owner_of> </man> </owner> </hat> <owl:ObjectProperty rdf:ID="owner_of"><owl:inverseOf rdf:resource="owner"/> </owl:ObjectProperty>
2) En : (It appears that) all birds fly in the same sky. //-> observation/belief (can be false) PL : ∃?s ∀?b ∃?f sky(?s) ∧ bird(?b) ∧ flight(?f) ∧ agent(?f,?b) ∧ place(?b,?s) CGLF: [proposition: [sky:*s] [proposition: [sky:*s]<-(place)<-[bird: @forall]<-(agent)<-[flight] ] ]. FCG: [a sky, place of: each ^(bird, agent of: a flight)]; FE : There is a sky that is place of each `bird that is agent of a flight´. FLnc: a sky place of: each ^(bird agent of: a flight); N3 : @forSome :s . @forAll :b . { [:s a sky] [:b a bird] } => {:b agent of a flight}. KIF: (exists ((?s sky)) (forall ((?b bird)) (exists ((?f flight)) (and (agent ?f ?b) (place ?b ?s))))) 3) En : By definition of the term "bird" by pm, birds fly. //definition -> cannot be false CGLF: pm#bird (*x) :=> [pm#bird: *x]<-(agent)<-[flight]. FCG: [any pm#bird, agent of: a flight]; FE : any pm#bird is agent of a flight. FLc : pm#bird agent of _[any->1..*]: flight; FLc : pm#bird agent of: flight __[any->1..*]; FLnc: pm#bird agent of: 1..* flight; N3 : pm:bird rdfs:subClassOf [a owl:restriction; agent of a flight]. //note: owl#restriction does not have a normal semantics: it is // an anonymous type when used as destination of a relation // between types (e.g., rdfs:subClassOf or owl#equal) // and otherwise it refers to "any" instance of this type KIF: (defconcept pm#bird (?b) :=> (exists ((?f flight)) (agent ?f ?b))) R+O/X: <owl:Class rdf:about="±bird"> <rdfs:subClassOf> <owl:restriction><agent_of><flight/></agent_of> </owl:restriction> </rdfs:subClassOf> </owl:Class> <owl:ObjectProperty rdf:ID="agent_of"><owl:inverseOf rdf:resource="agent"/> </owl:ObjectProperty>
Voici, en FL et en FL-DF ("DF": "Display Form"), l'union des 3 exemples précédents en supposant que dans les 2 premiers exemples "bird" réfère à pm#bird :
En: Tom -- a man -- owns a red hat and a pm#bird. (It appears that) all pm#bird fly in the same sky. By definition of the term "bird" by pm, birds fly. FL: Tom instance of: man, //in this page, "intance of" is used instead of "type" owner of: (a hat color: a red), owner of: a (pm#bird place: sky __[each<-a], agent of: a flight //implicitly: _[any->a] ); FL-DF: man --instance--> Tom <--owner-- a hat --color--> a red ^ a pm#bird --owner--| ^ |--instance-- pm#bird --place _[each<-a]--> sky |--agent _[any->a]--> flight FL-DF: /-> the man Tom <--owner-- a hat --color--> a red /--owner _[.<-a]-- pm#bird --place _[each<-a]--> sky |--agent _[any->a]--> flight