










Cours préparé par Dr Philippe Martin
http://www.phmartin.info/cours/GL/
Partie 0. Définitions, critères, principes de présentation informelle 0.0. Cas d'utilisation "UseCaseX" 0.1. Définitions générales : ..., paradigmes de programmation, ..., ordonnancement des tâches de développement (cycle de vie) 0.2. Critères fonctionnels/structurels de qualité logicielle (les "principes de conception" et le choix de langage (modèle + présentation formelle) sont dans la partie 1 du cours) 0.3. Quelques principes pour la présentation informelle ... 0.3.1. ... de l'interface textuelle/graphique (pour satisfaire "au mieux" le critère d'utilisabilité, à propos de l'IHM) : règles pour l'IHM citées dans le cours de coopération 0.3.2. ... du code (pour satisfaire "au mieux" le critère de lisibilité, sous-critère de maintenabilité) : 0.3.2.1. Style de programmation ; règle générale ; commentaires ; conventions de nommage ; indentation ; tests et messages d'entrée-sorties 0.3.2.2. Approches plus génériques et paramétrables
Voici le cas d'utilisation
[use case]
qui sera exploité dans ce cours.
Il sera référé sous le nom de UseCaseX.
Vous êtes employés de la
SSII
(Société de Services en Ingénierie Informatique) "SS2IX".
Pour des raisons économiques (entre autres), SS2IX souhaite réutiliser
au maximum
les composants logiciels qu'elle développe.
ClientX est un de ses clients réguliers.
Comme beaucoup de clients, il ne connaît (ou ne sait exprimer) ses besoins
qu'approximativement et ses besoins peuvent évoluer.
ClientX vient vous voir pour demander un logiciel - que nous appellerons logicielX -
ayant au moins la fonctionnalité suivante.
Xfct1 :
pour toutes les informations dans un ordinateur ou dans un répertoire ou,
parmi ces informations,
celles d'un certain média (e.g., textuel, image, ...) ou
celles identifiées par un certain nom (e.g., celles dont le nom finit par ".bmp")
- Xfct1.1 : afficher le nombre d'octets (nbBytes), de mots (nbWords) et
de lignes (nbLines) de ces informations ;
- Xfct1.2 : afficher "tous les mots ou certains des mots"
(e.g., le mot à la position positionOfTheWordToDisplay)
des lignes qui ont un certain mot (wordX)
plus d'un certain nombre de fois (maxNbWordXByLine) dans la ligne.
Si le nombre de ces lignes est inférieur à un certain nombre
(maxNbLinesWith_wordX ;
ClientX dit que ce nombre ne dépassera pas 100);
à la fin (que des lignes aient été affichées ou pas),
afficher
le nombre des lignes répondant aux critères
(nbLinesWith_maxNbWordXByLine) ;
- Xfct1.3 : faire en sorte que les moyennes (sur l'ensemble des informations) des
variables nbBytes, nbWords, nbLines et nbLinesWith_maxNbWordXByLine
puissent être affichées ;
- Xfct1.4 (new) : effectuer un search&replace
(en une seule commande).
Exercice oral : quelles précisions demanderiez-vous à ClientX ?
Exemples de questions de haut niveau : quelles sont les contraintes/variables financières, temporelles, logicielles (système d'exploitation, langage, temps de réponse, ...), algorithmiques (ordre de parcours des répertoires, liens symboliques, ...), de format pour les entrées et sorties (textuelle, graphiques, ...), etc. Réponse à prendre en compte pour l'exercice ci-dessous : les programmes doivent être indépendants du système d'exploitation.
Exercices à effectuer (-> programmer, tester avec "fenêtre d'erreur" ouverte,
documenter le source, ...) puis e-mailer à l'enseignant avant le début du
prochain cours (exercices non rendus ou incomplètement effectués -> 0/20).
Version finale à rendre au plus tard mardi 18/3/2014 midi
(1 fichier source par exo → 3 pièces jointes à votre e-mail, pas de .tar ni de .h ;
ces exercices sont très courts, ils ne nécessitent pas de .h ;
de plus, conserver leur lisibilité en les organisant en différentes sections via
des commentaires est un bon exercice ;
les règles des 5 pages de la section 0.3.2.1 doivent toutes être suivies ;
si vous utilisez du C, la fonction main() doit simplement décoder les
paramètres
et appeler une fonction générique ; l'entête de
chaque fichier doit entre autre
inclure un exemple de ligne de commande pour
compiler votre programme et
un exemple de ligne de commande pour tester votre
programme) :
Pour jeudi 27/2/2014, 10:00 :
Possibles solutions du dernier exercice,
tout d'abord en C++ avec les itérateurs C++
puis en C (commme demandé).
template<typename Thing> class Container
{ public std::vector<Thing> items;
Container (const char *s) { while (s++) items.push_back(*s); }
}
template<typename Thing> int nbElements (const Container &c)
{ int n= 0;
for (std::vector<Thing>::iterator iter= c.items.begin();
//-> iter points to an element of the container if it not empty
iter != c.items.end(); //-> an element of the container is pointed
iter++ //the equivalent with a linked list in C would be : iter= iter->next();
) n++;
return n;
}
Container someCharContainer("abcd"); //copy of "abcd" into this container
int n= nbElements(someCharContainer);
//note: for your code in C, to make the above copy, a function named
// "makeContainerFromString" may be used ; you then have to implement
// this function ; your container may "use" a linked list
struct Container { LinkedList items; }
int nbElements (const Container &c)
{ int n= 0; for ( ; c.items; c.items= c.items->next()) n++; return n; }
Container makeContainerFromString (const char *s) {...}
int n= nbElements(someCharContainer);
E.g.
(latin: exempli gratia) : "par exemple".
I.e. (latin: id est) :
"c'est-à-dire".
Vs. : "versus".
/ : "ou". // : "ou bien".
| : (quasi-)"alias" (entre 2 termes, dans le contexte où
ils sont définis).
Informatique
[computer science,
Information Technology (IT),
computing,
electronic data processing
] :
domaine/activité lié(e) au traitement automatique
de l'information par des machines.
Technologies de l'Information et de la Communication (TIC)
[Information and
Communication Technologies (ICT)] :
techniques utilisées dans le traitement et
la transmission des informations,
principalement de l'informatique, de l'Internet et des
télécommunications.
"TIC" est plus général que "Informatique"
mais "ICT" moins général que "Computing"
(-> le "et" ci-dessus est interprété différemment).
Information : données ou bien (représentations de) connaissances.
Connaissances [knowledge] : information organisée par des
relations sémantiques
(toute relation entre des sens de mots, e.g., la relation de
spécialisation,
sous-partie, localisation spatiale/temporelle, ...)
dans un formalisme logique,
ce qui permet à un logiciel de les exploiter
pour effectuer des inférences logiques.
Données [data] : information non
organisée ou de manière non "explicite",
i.e., non formellement ou sans relation sémantique.
Exercice (de contrôle ;
après réponse aux questions éventuelles des étudiants) :
- Un schéma de base de données est-il une représentation de
connaissances ?
Généralement non car un schéma ne représente généralement pas de relations sémantiques entre les objets (e.g., entre ceux représentés par des tables et ceux représentés dans leurs colonnes).
Système informatique
[information system
(domain: Information Systems)] :
système aidant la réalisation de tâches/décisions et
composé de
matériels [hardware] (ordinateur, périphériques, ...),
logiciels [software],
information et personnes.
Logiciel [software] : (ensemble de) programme(s) et informations associées.
Programme (informatique)
[computer program] :
suite de "phrases" (instructions ou descriptions)
[statements]
écrites dans un language de programmation (et/ou de modélisation),
et donc implémentant des
algorithmes
[algorithms],
i.e., des méthodes permettant
de calculer des
fonctions ou bien des procédures.
Les instructions|structures de contrôle
définissent (totalement ou partiellement)
l'ordre d'exécution d'autres instructions.
Progiciel : mot-valise,
contraction de "produit" et "logiciel", référant à un
logiciel applicatif, libre ou propriétaire,
"prêt-à-porter", standardisé et générique,
prévu pour répondre à des besoins ordinaires.
Language de programmation
[programming language] :
langage formel (permettant
d'écrire des programmes), donc ayant
- un modèle de langage (alias, ontologie de langage, i.e.,
un alphabet|vocabulaire, avec des définitions ou des règles de
composition,
formant une structure abstraite ayant une interprétation/sémantique
associée,
et suivant un paradigme de programmation),
- une présentation formelle (alias, structure concrète, syntaxe,
notation,
avec un
alphabet|vocabulaire de symbôles/mots
et une grammaire formelle).
Analyse (effectuée par un interpréteur ou compilateur;
cf. définitions ci-dessous) :
- analyse lexicale
- préprocessing
- analyse syntaxique [parsing]
- analyse sémantique
- génération de code.
Interpréteur
[interpreter] :
outil analysant et traduisant ou exécutant des programmes.
À la différence d'un compilateur (cf. définition ci-dessous),
un interpréteur n'effectue pas
une analyse sémantique (cf. définition ci-dessus) une fois pour toute,
il l'effectue seulement
pour les parties de code qu'il exécute
(cela dépend donc des données en entrée) et
à chaque fois qu'il les exécute.
Langage machine : suite de bits
représentant un programme et donc destinée à être
interprété par le processeur d'un ordinateur.
Langage machine virtuel, langage pour machine virtuelle, code octet [byte code] :
code (généralement binaire) exécuté par une
machine virtuelle, i.e., par
un programme
émulant les principales fonctionnalités d'un ordinateur.
Compilateur
[compiler] : programme qui,
à partir d'un code écrit dans un langage de programmation
créé un code équivalent mais écrit dans un langage plus facilement
exécutable,
typiquement un langage machine, un langage d'assemblage ou du code octet.
Généricité dans la programmation
[genericity in programming] :
usage de variables (et donc
d'entités de 1er ordre)
pour tout ce qui peut changer
dans le processus qui est programmé (i.e., qui est l'object de la programmation).
Choses liées à un processus (→ choses qui peuvent changer pour un processus ;
pour un schéma plus détaillé, cliquez ici) :
Time | Place | Process | State
(when, where, how long, before/after what, why/purpose/because)
↗
/time | place | from/to/before/after/during place/time/process | volume | ...
/
/
/ param | in | ... | out
Process ------------------------> Data parameter/input/material/instrument/output
| \ ("what, on/to/with what, how" for data)
| \
| \
| \sub/embedding-process | method | specializing/generalizing_process
| ↘
| Process | Description ("what, on/to/with what, how" for code)
| (-> data/control structures/types, functions de 1er ordre)
|
|
|agent/initiator | experiencer/recipient
V
Participant (who)
Paradigmes de programmation
[programming paradigms] :
styles de
programmation, fondés sur des "modèles de traitement"
[computation models]
différents. Les deux plus importants sont :
* La programmation impérative
(e.g., procédurale ou orientée-objet,
comme avec C, Java, PHP, ...) qui est fondée sur le modèle de la
machine de Turing
et qui décrit les traitements via des successions de "commandes". Celles-ci
"effectuent directement" - plutôt que "décrivent" - des changements sur des
états de ressources partagées (fichier, variables globales, ...) et ont
donc souvent
des effets de bord : appels
de commande/procédure identiques conduisant à des
résultats
différents.
* La programmation déclarative où ce sont les résultats
désirés qui doivent être
spécifiés plutôt
que la manière d'y parvenir : pas ou peu de contraintes peuvent être
spécifiées pour l'ordre des étapes|instructions|commandes
à effectuer, et les
changements d'états soit ne sont pas décrits (et sont donc gérés par
l'interpréteur)
soit impliquent de décrire et relier des contextes différents. E.g. :
- la programmation logique (i.e., basée sur une logique),
e.g., avec Prolog, KIF, ...
- la programmation fonctionnelle (i.e., basée sur la composition de
fonctions,
de préférence "pures", i.e., "sans état" :
sans modification de ressources partagées) ;
e.g., avec LISP, ML, Haskell, ...
- l'usage expressions régulières,
- l'usage de langages de requêtes (e.g., SQL, QUERY, SPARQL, ...), etc.
Pour culture, lisez ces pages :
- Comparison of programming paradigms
- LISP,
Standard ML,
Haskell,
Prolog,
Forth et
d'autres langages de programmation plus "ésotériques".
Exercice :
a. Les langages de description de formats (XML, ...) sont-ils déclaratifs ?
b. Sont-ils des langages de programmation ?
c. Permettent-ils des représentations de connaissances ?
d. Un programme C représente-t-il des connaissances ?
e. Un programme dans un langage logique représente-t-il des connaissances ?
f. Comme dans les exercices et exposés de
votre cours de coopération
au semestre précédent,
et donc conformément aux règles de bases rappelées page suivante, reliez
(graphiquement et dans le langage FL) par des relations ">" (sous-type) et "part"
les différents types de paradigme et de langage de programmation référés
précédemment.
a. Oui b. Non car ils ne peuvent pas être utilisés directement pour implémenter des algorithmes. Toutefois, des langages tels XML peuvent être utilisés pour rendre explicite et formatter des structures abstraites de langages et peuvent donc être utilisés pour définir des structures concrètes de langages. c. Uniquement si utilisé pour encoder des structures concrètes de langages de représentation de connaissances. d. Non. Une hiérarchie de classes dans un programme C++ ou Java est toutefois une forme très limitée de représentation de connaissances. e. Oui, de manière plus explicite|organisée suivant les programmes. f. paradigme_de_programmation //(le type) paradigme_de_programmation > (programmation_impérative // a pour sous-type programmation_impérative qui > (programmation_procédurale // a pour sous-type programmation_procédurale langage: 1..* (. langage_de_programmation_procédurale > C PHP) ) //=> toute programmation_procédurale a pour langage 1 à plusieurs instances du // type langage_de_programmation_procédurale, lequel a pour sous-types // C et PHP (entre autres) (programmation_orientée_objet alias: POO, langage: 1..* (. langage_de_programmation_procédurale_permettant_la_POO > Java (C++ partie: 1..* C) ) ) ) (programmation_déclarative //autre sous-type direct de paradigme_de_programmation > (programmation_logique langage: 1..* (. langage_de_programmation_logique > Prolog KIF) ) (programmation_fonctionnelle langage: 1..* (. langage_de_programmation_fontionnelle > LISP ML Haskell ) ) );
Règles de base pour la représentation de connaissances
(règles à suivre dans tous vos exercices de modélisation ;
ce sont les règles déjà vues au début de la section 2.6 du cours de coopération) :
1. Une relation binaire de type *rt (e.g., 'subtype' or 'part')
depuis un nœud source *s (e.g., 'feline' or 'at least 80% of car')
vers une destination *d (e.g., 'cat' or 'at most 100 wheel') se lit :
" *s has/have for *r *d ". E.g. :
`feline > cat´ (i.e., `feline subtype: cat´) se lit
"feline has for subtype cat"
(ou "the type feline has for subtype the type cat"),
`at least 80% of car part: at most 100 wheel´ se lit
"at least 80% of cars have for part at most 100 wheels".
Ce dernier exemple peut aussi se lire :
"at least 80% of instances of the
type car have for part
at most 100 instances of the type wheel". Enfin,
conformément à la règle 7 ci-dessous,
`car part: at most 100 wheel´ se lit
"any (instance of) car has for part at most 100 (instance of) wheel(s)".
2. Si *r est suivi de "of" (pour inverser la direction de la relation), il vaut mieux lire
" *s is/are *r of *d ".
E.g., `cat < feline´ (i.e., `feline subtype of: cat´) se lit
"cat is subtype of feline" et `at least 51% of wheel part of: a car´ se lit
"at least 51% of wheels are part of a car".
3. `*st subtype of: *t´ (alias, `*st < *t´) est équivalent à
`any *st instance of: *t´,
i.e., ` `*i type: *st´ => `*i type: *t´ ´ (3ème paraphrase,
informelle cette fois :
"*st est sous-type de *t ssi toute instance de *st est aussi instance de *t").
4. `*t > excl{*st1 *st2}´ <=> `*t > *st1 (*st2 exclusion: *st1)´
(informellement :
*st1 et *st2 sont sous-types de *st et ne peuvent avoir ni sous-type commun,
ni instance commune).
5. Si le nœud destination d'une relation est source/destination d'autres relations,
il faut isoler ce nœud destination et ses autres relations avec des parenthèses
(comme
dans l'exemple du paragraphe précédent) pour que
l'interpréteur du langage puisse
savoir que ces autres relations sont
sur le nœud destination et pas le nœud source.
Similairement, dans une notation textuelle, lorsque 2 relations de même source se
suivent, il faut les séparer par un symbôle (en FL, c'est la virgule ; voir
les exemples).
6. Les noms utilisés dans les nœuds relation/source/destination doivent être des
noms communs/propres (jamais d'adjectif, verbe, ...) au singulier et en
minuscules (sauf pour les noms propres s'ils prennent normalement des majuscules).
7. Les relations qui ne sont pas entre types et/ou des individus nommés
(i.e., pas les relations sous-type/instance mais la majorité des relations)
doivent préciser comment les nœuds source et destination sont quantifiés
Exemples de quantificateurs : "a" (i.e., "there exists a"), "any" (i.e., "by definition, each"),
"every" ("by observation, each"), "most" (i.e., "at least 51%"), "at most 20%",
"0..20%", "at most 20", "0..20", "between 2 and 3", "2..3".
Toutefois, si le quantificateur du nœud source est 'any' - i.e., s'il s'agit d'une
définition -
celui-ci peut être omis : c'est le quantificateur par
défaut pour un nœud source.
Pour le nœud destination, 0..* est le quantificateur par défaut. Donc :
`car part: wheel __[any->0..*, 0..*<-any]´
=> (`any car part: 0..* wheel´ <=>
`car part: 0..* wheel´)
8. Si vous hésitez entre 2 relations dont une seule est transitive, choisissez la
transitive.
Sinon, si vous hésitez entre 2 relations, choisissez la plus basique|générique
(et
utilisez des nœuds concept adéquats pour ne pas perdre en
précision).
Notions de langage "plus évolué" et de "bas niveau" :
* Les (langages) assembleurs
(langages de
1ère génération
ou de
2ème génération)
sont impératifs et ils ne sont pas évolués car ils sont
structurellement proches du
langage machine
(binaire; directement exécutable par un microprocesseur).
En effet, un assembleur a généralement 1 mnémonique pour chaque
commande du
jeu d'instruction. Ce sont essentiellement des
opérations arithmétiques/logiques ou
de contrôle, dont le "jump|goto" et l'appel de procédure.
Il est donc très facilement compilable ou
interprétable, i.e.,
traduisible en langage machine.
* Les langages de 3ème génération,
les 1ers dits de "haut niveau" (au sens de évolué),
sont ceux qui
bannissent l'usage du "jump|goto" au profit de structures de contrôle plus
évoluées comme le "while", "for", "switch", ... et l'appel de procédure.
Ce sont donc des langages de programmation impérative (et procédurale) structurée.
* Plus généralement, un langage est plus évolué qu'un autre s'il
offre des
constructions (types d'instructions ou de descriptions) plus abstraites/expressives, i.e., si
grâce à elles, plus d'inférences logiques ou autres opérations
- peuvent être effectuées par un moteur d'inférences ou le
compilateur//interpréteur ; ou
- peuvent être représentées, e.g., concernant les fonctions, le C est +
évolué que Java car
une fonction est une entité du 1er ordre
(i.e., elle peut être mise dans une variable)
en C - via les "pointeurs sur fonctions" - alors que ce n'est pas le cas en Java ; ou
- doivent être opérées par le compilateur//interpréteur pour
traduire ces constructions en assembleur ou langage machine.
Les langages déclaratifs ont donc des constructions plus évoluées que les
langages impératifs. Les langages de
5ème génération sont déclaratifs.
Ceux dits de
"4ème génération" sont le plus souvent impératifs
mais accompagnés d'un
Environnement de programmation/développement intégré
[Integrated Development Environment
(IDE)].
Il y a une équivalence
("correspondance de
Curry-Howard") entre des systèmes de
i) déduction logique,
ii) vérification de types (dans les langages fonctionnels), et
iii) preuve de programme. Toutefois, les langages logiques permettent
d'exprimer
toutes sortes de relations, pas seulement des fonctions.
* Un langage est parfois dit "de bas niveau" si son jeu d'instructions
permet aussi
d'effectuer des opérations sur des bits
(ET, OU, décalage, ..). Le C est donc aussi un
langage de bas niveau
mais n'est pas "moins évolué" que le langage Pascal.
Le C est moins évolué que C++.
Toutefois, l'expression "(plus) haut niveau" [high(er) level] est très
souvent utilisée
dans le même sens que "(plus) évolué".
Exercice :
Un langage évolué de bas niveau ...
A) est un assembleur
B) est moins évolué qu'un langage évolué de haut niveau
C) a des instructions permettant de manipuler les bits, un par un
D) les 3 dernières réponses
E) aucune des 4 dernières réponses
Réponse C
Génie logiciel
[software engineering] :
ingénierie du
développement de logiciel
[software development] ->
l'ensemble des
"activités de conception et de mise en œuvre des produits et des
procédures
tendant à rationaliser la production du logiciel et son suivi"
[arrêté ministériel du 30.12.1983].
But principal: arriver à ce que des logiciels de grande taille
correspondent aux
attentes du client, soient fiables, aient un coût d'entretien réduit
et de bonnes
performances tout en respectant les délais et les
coûts de construction.
Les tâches|processus principaux de
développement|conception de logiciel
[software development process]
sont celles du plan de ce cours de GL1:
1. Modélisation|analyse|spécification & conception
(-> partie 1 du cours)
1.1. Analyse & spécification des besoins
(fonctions que devra offrir le logiciel)
1.2. Conception du logiciel (ses mécanismes) et de ses
bases d'informations
[software design and
knowledge/data base design]
2. Opérationnalisation|réalisation|programmation
[programming]
2.1. Codage|implémentation|construction
[implementation|coding]
dont le
prototypage
[prototyping] et la
gestion de versions
2.2. Intégration,
vérification par analyse ou
test
[software testing],
débogage [debugging]
et optimisation
("validation" et "vérification" sont parfois distinguées mais hélas différemment, e.g., :
- validation : a. via des tests, ou bien
b. revues, prototypage ... -> conformité aux attentes du client
- "vérification" : a. via la lecture de modèles/documentation et de code
b. revues, tests, preuves -> conformité aux spécifications)
3. Déploiement|livraison
[software deployment]
(dont la
documentation pour utilisateurs
, le packaging et le
licensing),
maintenance
[maintenance] et
refactorisation
Exercice :
a. Quelles tâches doivent être documentées ?
b. Donnez, en 1 ligne de script shell, un exemple de prototype pour Xfct1.1.
a. Toutes.
b. find . -P -type f -name '*.bmp' -exec wc -c -w -l '{}' \;
-P : "Never follow symbolic links" ; "-type f" : select only 'regular' files
find offers many options for selecting file on their types, creation/modification/... dates, ...
do "man find" to list the options and show+explain different possibilities to the client
Ordonnancement des tâches de développement
[software life cycle] :
lié aux coûts et besoins
de revenir sur une tâche antérieure, compte-tenu
du temps et nombre de personnes impliquées dans chaque étape, et de
la facilité (pour les clients et/ou analystes) de spécifier le produit.
Les grandes familles|méthodologies :
- Modèle en cascade
[waterfall model] :
pas de retour car les tâches sont de
+ en + compliquées et coûteuse par rapport à celles qui les
précèdent,
comme dans le BTP (Bâtiment et Travaux Publics).
- Cycle en V (voir figure page suivante) :
le document ou logiciel créé à chaque
étape est soumis à une revue approfondie avant de passer à
l'étape suivante,
et sert au tests après implémentation.
On ne voit ne voit tourner quelque chose qu'à la fin : c'est
l'effet tunnel.
Cette approche suppose peu de besoins de changements
de choix antérieurs
-> détection tardive d'erreurs d'analyse/conception.
En GL, plus de retours (via des prototypes, ...) sont souvent nécessaires car :
- le client ne connaît (ou ne sait exprimer) ses besoins qu'approximativement
et ceux-ci peuvent évoluer,
- les développeurs ne comprennent pas bien les besoins du client,
sont remplacés ou font de mauvais choix technologiques.
- Cycle en spirale
[spiral model] (pour projets + risqués ou
testant des alternatives) :
à
chaque spire, itération sur les phases
d'analyse, conception, codage et test
-> retours via des versions successives de + en + détaillées d'un produit.
- Cycle semi-itératif
[incremental build model] :
itérations courtes lors du codage,
e.g., les méthodes Agile
(dont Scrum et
l'extreme programming)
et les méthodes
"plus basées sur la création de prototypes" dites
Rapid Application Development
(RAD; cliquez sur ce lien pour une comparaison des méthodes).
- cycle itératif
[iterative model] :
itérations selon le cycle
"planifier->développer->contrôler->ajuster->planifier->..."
Le cycle en V :

Illustration de l'importance d'être précis dans toute communication :
spécification, programmation, création de message d'erreurs, ...
 |  |
There are two ways of constructing a software design: one way is to make it so simple that there are obviously no deficiencies; the other way is to make it so complicated that there are no obvious deficiencies. (C.A.R. Hoare)
A computer language is not just a way of getting a computer to perform operations but rather that it is a novel formal medium for expressing ideas about methodology. Thus, programs must be written for people to read, and only incidentally for machines to execute. (The Structure and Interpretation of Computer Programs, H. Abelson, G. Sussman and J. Sussman, 1985.)
Programming (and hence learning to program) IS NOT (just) about coding a program that seem to solve a given problem for the case you have thought about, it IS about creating a SCALABLE program that take into account as many situations as possible and delivers good/helpful error messages for all the different kinds of bad input that the user can enter. Scalable implies - READABLE (clear, concise, consistent in following conventions) - MODULAR (as in "one function per task" and "no more than 30 lines per function" and "no more than 10 lines outside functions"; modularization also helps readability and re-usability). It should be remembered that the initial development of a program is usually a small fraction of the time and cost that is spent on it (later maintenances and extensions is where most of the time is spent, even when good programming languages are used and good programming methodologies are followed).
Le Génie Logiciel (GL) débute vers 1968 avec les
problèmes de la
"crise du logiciel" (à lire),
i.e., les difficultés rencontrées
dès la création des premiers gros logiciels : difficultés de
- réalisation de plannings (-> produits non terminés dans les temps),
- maîtrise des coûts/délais de réalisation et de maintenance
- qualité des logiciels (-> produits peu adaptés/fiables/performants).
Ces gros logiciels étaient rendus possibles par la puissance de
calcul/mémoire des
circuits intégrés.
Leurs problèmes vinrent d'un manque de méthodologie de conception.
Cliquez ici pour des compléments d'information sur les points de la partie 0
de ce cours (à lire).
Cliquez ici pour une liste de "bugs"
ayant eu des conséquences graves ; beaucoup auraient
pu être évités si les outils (langage, compilateur, méthodologie, ...)
utilisés avaient été plus
"stricts" et donc plus "formels".
Répartition moyenne des coûts de production selon Boehm (1975) :
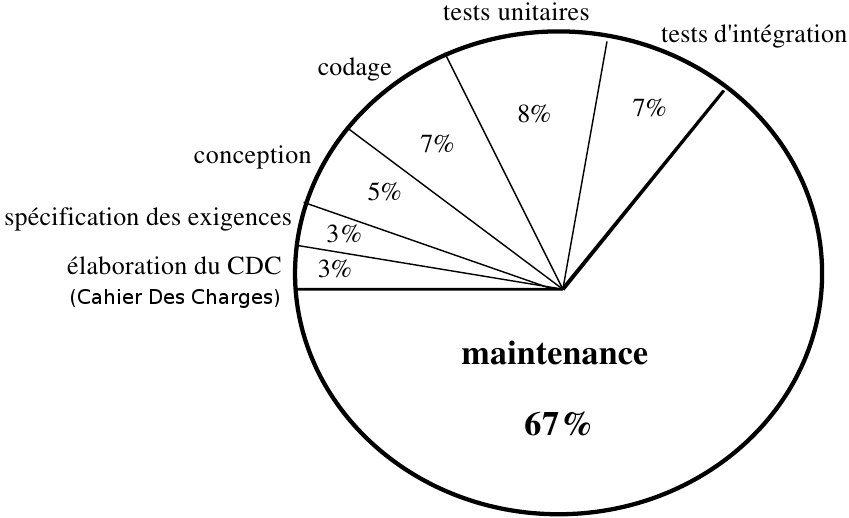
- 45% des efforts pré-maintenance pour tester&corriger une mauvaise
spécification/conception
(64% des erreurs sont des erreurs d'analyse/conception ; 36% d'erreurs de codage)
- coût de correction d'erreurs : 50% coût total de production
(coût 'erreurs de spécification' > coût 'erreurs de conception'
> coût 'erreurs de codage')
- coût exorbitant de gestion de versions multiples
- 40%-80% du coût
d'un logiciel est dans sa maintenance.
Quelques
croyances
erronées sur le développement de logiciels :
* un logiciel peut être construit uniquement par assemblage de composants
logiciels
(non, les composants sont loin d'être suffisamment
adaptables/combinables, complets
et sémantiquement organisés)
* ajouter des personnes à une équipe d'ingénieurs permet de
rattraper le retard
(non, car il faut les former, les temps de
communication sont proportionnels à N*(N-1)
- N étant le nombre de personnes impliquées - et beaucoup de tâches
ne sont pas
partitionables ;
loi de Brooks)
* le travail est terminé une fois que le logiciel fonctionne
(non, même avec une génération semi-automatique du code, une
grosse partie du
travail est dans la maintenance).
Critères|facteurs fonctionnels (de qualité) : conformité par
rapport aux spécifications et
donc aussi par rapport aux besoins des
utilisateurs. Ceci est généralement mesuré via des tests.
Critères structurels :
critères non-fonctionnels
(de qualité). Leur satisfaction provient
essentiellement du respect
de bonnes pratiques architecturales. Les plans pour les
satisfaire sont donc
dans le modèle architectural plutôt que dans le modèle de conception.
Les pages suivantes distinguent :
Exercice :
- la testabilité et la portabilité sont-ils des critères de qualité ?
- si oui, à quel grand critère pensez-vous qu'ils soient reliés ?
- voyez-vous d'autres grandes catégories de critères (structurels ou non) ?
Oui, ce sont des sous-critères de celui de maintenabilité (cf. page suivante).
Premiers critères de "sûreté de fonctionnement"|[dependability] mais pas de "[security]" :
Suite des critères de "sûreté de fonctionnement"|[dependability] mais pas de "[security]" :
Oui puisque la définition ci-dessus du critère de sécurité|[safety] réfère à de la "fiabilité|[reliability]" en ajoutant une contrainte supplémentaire : "pour les erreurs/fautes catastrophiques".
Premiers critères de "sûreté de fonctionnement"|[dependability] et de "[security]" :
Si ces 2 mesures ont des contraintes|définitions similaires (e.g., "mesure par ratio du temps" et "lorsqu'un état de panne n'est pas plus sûr qu'un état de fonctionnement"), celle de "disponibilité" peut s'avérer être une spécialisation de celle de "fiabilité". Toutefois, comme indiqué ci-dessus, les sens/mesures de "disponibilité" et de "fiabilité" sont trop divers (et parfois même antagonistes) pour permettre de classer "disponibilité" comme spécialisation de "fiabilité".
Oui puisque la définition ci-dessus du critère d'accessibilité réfère à de l'accessibilité en ajoutant une contrainte supplémentaire : l'accessibilité au plus grand nombre.
Suite des critères de "sûreté de fonctionnement"|[dependability] et de "[security]" :
Critère de "[security]" mais pas de "[dependability]" :
Exercice :
- la "protection de la vie privée" peut-elle être un critère spécialisant
celui de "confidentialité" ?
La "protection de la vie privée" réfère tout d'abord à une tâche. Une tâche ne peut spécialiser un critère. Si l'on définissait un critère "protection de la vie privée", ce critère pourrait spécialiser celui de "confidentialité" si l'on arrivait à lui donner une définition qui ajoute des contraintes par rapport à celle de "confidentialité".
Exemples d'autres critères structurels de qualité d'un système d'information (S.I.) :
Exercice :
- représentez (graphiquement ou en FL) les liens de spécialisation entre les critères
de qualité
cités dans cette section 0.2.
critère_de_qualité
> excl
{ (critère_fonctionnel_de_qualité
> (utilisabilité //"satisfaction" de l'utilisateur (-> inclut "originalité")
> comprehensibilité opérationalité //... pour aller plus loin, il faudrait
) // préciser le sens de ces termes
(capacité_fonctionnelle
> (pertinence > généralité) exactitude //... même remarque
)
)
(critère_structurel_de_qualité
> excl
{ (sécurité_au_sens_large
> (sûreté_de_fonctionnement //dependability
> (sûreté_de_fonctionnement__et_pas__sécurité_au_sens_classique
> maintainabilité (fiabilité > safety) )
(sûreté_de_fonctionnement__et__sécurité_au_sens_classique
> (disponibilité > accessibilité)
(intégrité > authenticité) imputabilité
)
)
(sécurité_au_sens_classique
> sûreté_de_fonctionnement__et__sécurité_au_sens_classique
(sécurité_au_sens_classique__et_pas__sûreté_de_fonctionnement
> (confidentialité > vie_privée) anonymat
)
)
)
(critère_lié_à_la_performance
> efficience-rendement-rentabilité complexité_algorithmique
)
}
)
};
software_quality_criteria < description_medium,
> excl
{ (software_functional-quality_criteria
> (usability > learnability operability)
(functional_suitability
> functional_appropriateness functional_correctness functionality_compliance
)
)
(software_structural-quality_criteria
> excl
{ (software_general-security_criteria
> (dependability
> (dependability_and_not_security
> (maintenability > testability observability stability
modifiability (reusability > modularity) )
(reliability
> robustness fault_tolerance recoverability
(resilience > survivability)
safety (^reliability in case of catastrophic failure^)
)
)
(security_and_dependability
> (availability > accessibility)
(integrity > authenticity) accountability
)
)
(security
> security_and_dependability
(security_and_not_dependability > (confidentiality > privacy)
unlinkability anonymity
)
)
)
(software_general-performance_criteria
> performance_efficiency/effectiveness/engineering
algorithmic_efficiency
)
}
)
};
Exemples d'organismes produisant des normes+certifications de qualité de logiciels :
- AFNOR (Association Française de Normalisation -> e.g., norme NF ISO/CEI 9126, 1992)
- ANSI (American National Standard Institute)
- DIN (Deutschen Institut für Norming)
- DOD (Department Of Defense)
- IEEE (Institute of Electrical and Electronic Engineers)
- ISO (International System Organization)
Exemples de modèles pour mesurer/améliorer la qualité de logiciel
(et plus généralement les processus d'un projet ou d'une organisation) :
- le Capability Maturity Model Integration (CMMI) du
Software Engineering Institute (SEI) de Carnegie Mellon University (CMU)
- la méthode COCOMO (COnstructive COst MOdel) qui,
l'année scolaire 2011-2012,
fut introduite dans le cours GL2, de même que la méthododologie de tests,
l'analyse de risques, et
les documents d'analyse&conception dans le cadre
d'une démarche cyclique basée sur des objets, notamment avec UML.
GL1 est plus focalisé sur les "principes génériques"
et "bonnes pratiques" (à
suivre ou utiliser pour effectuer des choix)
de modélisation et de codage.
Bonnes pratiques de programmation
[best coding practices] :
ensemble de règles informelles (-> non contrôlables par un
compilateur/interpréteur)
destinées à améliorer la qualité d'un logiciel et simplifier sa
maintenance ainsi que sa
ré-utilisabilité.
Elles incluent "règles|conventions de style de programmation" et
"principes+patrons de conception".
Comme 40%-80% du coût d'un logiciel est dans sa maintenance, elles sont
très importantes.
Plus un développeur ou une équipe de développement
adopte de telles règles,
mieux c'est.
Il faut les suivre de manière systématique (<-> pas de style incohérent ).
Style de programmation
[programming style] :
ensemble de règles|conventions de codage (et souvent de présentation informelle)
facilitant la compréhensibilité d'un code et l'évitement d'erreurs.
Elles peuvent souvent être vérifiées par un
"vérificateur de style" [Checkstyle tool].
Rien n'est pire que l'absence de style ou l'incohérence dans le suivi de règles.
Les paragraphes suivants pour cette section concernent uniquement la
présentation informelle.
Quote:
A computer language is not just a way of getting a computer to perform operations
but rather that it is a novel formal medium for expressing ideas
about methodology.
Thus, programs must be written for people to read, and only incidentally for
machines to execute.
("The Structure and Interpretation of Computer Programs",
H. Abelson, G. Sussman and J. Sussman, 1985).
Rappels de
règles citées dans le cours de coopération.
1. Plus un langage/protocole/outil permet de représenter et d'exploiter
des objets d'information fins (référables et sélectionnables) et
des méta-données précises sur ces objets
(représentations de connaissances, politiques de contrôle
d'accès/usage, ...),
mieux c'est.
2. Séparer l'information (son contenu) de sa présentation (multimédia) :
pour
- faciliter les changements de présentation par les programmeurs et les utilisateurs,
- faciliter l'exploitation automatique de l'information.
Principaux outils actuels:
- des schémas/modèles/langages pour décrire des structures
(e.g., XML), et
- des schémas/modèles/langages pour décrire des présentations
(e.g., CSS, XSLT).
Lorsqu'utilisés directement, les langages de description de structures de
documents, tels XML,
ces outils ne permettent de représenter qu'une fraction très
faible de la sémantique de l'information et
ils ne permettent pas de la représenter d'une manière qui passe à l'échelle.
En effet, comme ils utilisent une structure d'arbre au lieu d'une structure de
graphe, ils ne permettent
pas - ou n'encouragent pas - une représentation explicite de relations
sémantiques entre objets d'information.
Ceci est détaillé dans la section 1.0.7.
3. Des techniques de personnalisation
doivent être utilisées pour
- proposer différents modèles basés sur des groupes/profils,
- proposer des recommandations basées sur les comportements passés
de l'utilisateur ou
basées sur des préférences d'autres
gens (filtrage collaboratif),
- permettre aux utilisateurs d'adapter l'interface directement.
Corollaire de la règle No 1 (page précédente) :
plus les éléments de l'IHM et du contenu sont séparés,
plus ils sont fins, adressables et précisément représentés (organisés),
plus il est possible de permettre leur personnalisation par chaque utilisateur.
Donc :
- un logiciel doit fournir une liste organisée de paramètres de présentation et
un langage adapté pour la présentation
- la caractéristique la plus importante d'une IHM est que
tous les objets liés à un objet particulier
doivent être facilement accessibles à partir de lui.
-> idéalement, chaque objet "intéressant" doit pouvoir être
sélectionné et
sa sélection par un utilisateur conduire à un
menu déroulant contextuel
(e.g., via un menu pop-up) permettant à l'utilisateur
d'explorer, sélectionner et ajouter/modifier tous ses objets reliés,
e.g.,
ses propriétés de présentation, des objets informationnels et
les actions qui peuvent être faites sur cet objet ou via cet objet
(pour les objets reliés qui n'ont pas trait à la présentation,
les modifications doivent
être sans perte ; cf. la
section 2.6.4 du cours de coopération).
Dans des éditeurs de documents structurés bien conçus, cela est possible
mais
l'ensemble des objets reliés est limité à ceux identifiés par les
schémas de
structure, de présentation et d'interaction/événement associés au
document en
cours d'édition.
Pour un meilleur partage/recherche des connaissances et une
meilleure coopération,
les objets doivent être représentés dans une base de connaissances (BC),
et donc
le menu contextuel associé à un objet sélectionné devrait
permettre l'exploration de
la BC à partir du point d'entrée constitué par cet objet.
Règle générale pour le code (composants logiciels, ...) et ses modèles :
pour représenter/programmer une information, il vaut toujours mieux le faire
- dans le langage utilisé pour les entités formelles,
- le plus formellement possible,
- à défaut, sous forme d'annotations (et, à défaut, sous forme de
commentaires),
- dans tous les cas, en utilisant des termes en anglais plutôt qu'en français
(e.g., pour être compris - et donc être plus ré-utilisable - par
plus de personnes).
Similairement, plus la documentation informelle peut être générée à partir
de
représentations formelles, mieux c'est (pour les développeurs et les utilisateurs).
Commentaires [comments] :
les parties informelles d'un programme (ou
d'une base d'informations) qui ne sont pas associées de manière formelle (i.e., dans
un langage formel) à des entités formelles.
Les annotations sont les parties informelles
associées de manière formelle
(donc exploitables automatiquement), e.g.,
celles utilisées par le compilateur Java.
Les commentaires - et, souvent, les annotations - sont ignorés par un
compilateur/interpréteur de programme (quoique Java utilise certaines annotations
pour certaines vérifications).
Par contre, l'interpréteur d'une base d'information n'ignore que les commentaires :
il stocke les annotations avec les entités auxquelles elles sont associées.
Conformément à la règle générale ci-dessus,
un commentaire ne doit être
utilisé pour spécifier une information que lorsqu'il est impossible de
la spécifier autrement, e.g.,
- via des préconditions, post-conditions et messages d'erreur
- via des identifiants explicites suivant des conventions de nommage
- via des annotations (si le language de programmation le permet).
Un commentaire doit apporter de l'information par rapport au code,
il ne doit donc jamais le paraphraser.
Via des commentaires ou des annotations, chaque entête de module (et,
a fortiori,
de programme) doit au moins indiquer
- son/ses créateurs (-> email, home page),
quand il a été créé et modifié, et pourquoi
e.g., pour un fichier HTML :
<meta name="Author" content="email et/ou home page">
pour un fichier texte :
Author: Philippe Martin (www.phmartin.info)
- comment l'appeler (-> exemples d'appels)
- comment le tester (-> noms des fichiers de tests).
Via des commentaires ou des annotations, un programme doit être séparé en
différentes sections (par exemple comme dans
ce fichier afin faciliter la
distinction ou recherche de ses différentes parties, e.g.,
"Data structures and
associated methods", "Application-dependent classes and functions",
"Other classes and functions".
Conventions de nommage
[naming conventions] :
règles pour la création d'identificateurs (de types, variables, fonctions, ...)
dans un programme et sa documentation.
Il vaut mieux utiliser des identificateurs très explicites (donc très longs)
que d'utiliser des annotations
- c'est une application de la règle générale de la page précédente,
- cela évite aussi au lecteur d'aller chercher l'annotation,
et donc simplifie sa vie et/ou évite des erreurs.
Il faut suivre une méthode de nommage systématique et, si possible,
de manière formelle.
* L'approche orientée objet facilite cela. C'est un de ses apports.
Imitez ce style lorsque vous ne pouvez utiliser l'approche orientée objet, e.g.,
si vous ne pouvez écrire "personX.dateOfBirth_set()",
écrivez
"Person_dateOfBirth_set(personX,dateOfBirthX)"
* Avec des langages de représentation de connaissances, il faut
- utiliser la capitalisation usuelle des mots,
- séparer les mots par des délimiteurs (e.g., '_') plutôt que d'utiliser
le
style "InterCap"|"CamelCase"
car ce dernier engendre une
perte d'information (difficilement récupérable),
- ajouter "type" à la fin des types du second-ordre.
* Avec les langages de programmation, les noms de types, classes et
variables globales doivent commencer par une majuscule.
Seules les noms de constantes doivent être entièrement en majuscules.
* Les identificateurs de fichier étant des identificateurs de constantes dans
certains programmes (e.g., des scripts shell),
ne mettez jamais
d'espace, de caractères accentués
et, plus généralement, de caractères non ASCII)
dans vos noms de fichiers.
Donnez toujours une extension (e.g., ".txt") à vos noms de fichiers,
à part éventuellement aux fichiers directement exécutables.
Indentation:
usage des espaces, e.g., pour faciliter la visualisation des blocs.
Il faut choisir un style et le suivre systématiquement.
Quelques bonnes règles sont :
* Pour des raisons de portabilité :
- ne pas dépasser 78 caractères par ligne
(→ utilisez seulement 2 espaces pour indenter un nouveau bloc)
- ne pas utiliser
de "tabulations physiques" [hard tabs], i.e.
ne pas utiliser la touche "tabulation" sauf si elle génère
des espaces normaux
- utiliser un "éditeur de texte pur (ASCII)" pour écrire les programmes,
jamais un "éditeur de document" général comme par exemple Word.
* Pour des raisons de symétrie
- aligner les parenthèses/crochets/accolades (qui se correspondent) en
colonne/ligne,
sauf s'il s'agit de parenthèses délimitant des
paramètres de functions (appel/définition);
il s'agit du
style Horstmann
(ou style Allman
-- alias style BSD -- si l'accolade ouvrante
est seule sur une ligne, ce qui est à éviter car cela est une
inutile perte d'espace et donc
de travail supplémentaire pour la
visualisation/comparaison/compréhension/ré-utilisation
de fonctions);
- écrire "a==1" ou "a == 1" pas "a ==1" ni "a== 1".
* Pour des raisons d'asymétrie et pour faciliter vos recherches
- écrire "a= 1" pas "a =1" ni "a=1" (sauf pour gagner de la place,
e.g., dans la partie
initialisation d'une boucle "for")
- écrire "int fct (...) {...}" pas "int fct(...) {...}"
et "fct(...);" pas "fct (...);"
- dans une déclaration de fonction, si le langage ne vous le permet pas,
indiquer en commentaire le type des variables et
si oui ou non ce sont des variables d'entrée et/ou de sortie, e.g.,
int fct (/*inP*/..., /*varP*/..., /*outP*/) {...}
* Pour des raisons de concision (et donc de lisibilité) :
- ne pas sauter de ligne dans une fonction/procédure.
* Pour des raisons de lisibilité et de structure (et donc de compréhensibilité,
maintenabilité, ...) :
- utiliser des fonctions (plutôt que des procédures) les + courtes possibles
-> de préférence 2 lignes, jamais plus de 20 lignes
- du code source généré (par un de vos programmes) doit sastifaire les mêmes
conventions et contraintes de lisibilité que vos autres programmes.
Tout tester : paramètres, résultats d'une fonction si la fonction ne les teste pas
elle-même, ...
En début/fin de fonction : test des préconditions et des postconditions
-> intérêt d'avoir des fonctions très courtes qui font elles-même leurs tests.
Donnez des messages d'entrée-sortie (dont les messages d'erreur) "explicites", i.e.,
avec toutes les informations nécessaires permettant à un utilisateur de comprendre
le message
(idéalement, sous la forme d'un "menu déroulant contextuel" permettant de naviguer
la base de connaissances sous-jacente au code pour comprendre les relations entre
les différents objets et fonctions). E.g.,
- un message d'erreur ne doit pas dire "ce que vous avez entré n'est pas valide" mais
"vous venez d'entrer ceci : ... ; cela ne correspond pas au format attendu qui est : ..."
- un résultat (e.g., un nombre) doit toujours être précédé d'une phrase
expliquant
de quoi il s'agit
- une demande d'entrée doit toujours mentionner (ou référer) le format attendu
et
les "valeurs par défaut" qui seront prises en compte.
pm#structure_map := "generic function for any collection traversal/... (-> generalizes most functions); way to create a fully generic and easy-to-search software component library; see also: lselectAndExploit.js (alias, "search & perform") + comments; the equivalent object-oriented alternatives are - to use a Structure_map class, - to group function parameters via a Navig object with various constructor/init methods (with different parameters; flexible memory allocation technique; return Null if error), - more commonly, to give at least 1 for/foreach method to each structure", pm#input: 1 pm#structured_object ?input_structure 0..1 pm#function_with_input_a_structure_and_an_index ?fctToApply/*?s,?i*/, 0..1 pm#boolean_function ?fct_isAtStructureEnd/*?s,?i*/ 0..1 pm#function_returning_a_structured_object ?fct_accessElement/*?s,?i*/ 0..1 pm#function_with_input_a_structure_and_an_index ?fct_inputSuccessor/*?s,?i*/ //E.g., string_left-to-right_next_uppercase_char_from_3rd_char_to_4th'A'() 0..1 pm#index ?index 0..1 pm#function_returning_an_index ?fct_nextIndex/*?i,(?s)*/ 0..1 pm#output_aggregation_function_for_structure_map ?fct_outputAggregation /*?r,?i*/ //sets a successor relation between the results or aggregates them 0..1 pm#index ?outputIndex 0..1 pm#function_returning_an_output_aggregation_type ?outputAggregation_type 0..1 pm#structured_object ?future_output_structure, pm#output: 0..1 pm#structured_object ?output_structure, > (pm#fct_applying_a_function_to_a_structure pm#input: 1 pm#structured_object ?input_structure 1 pm#function_with_input_a_structure_and_an_index ?fctToApply/*?s,?i*/, > excl { (pm#fct_applying_a_function_to_an_indexed_structure = pm#fct_indexed-based_map, pm#input: 1 pm#structured_object ?input_structure, 1 pm#function_with_input_a_structure_and_an_index ?fctToApply 0..1 pm#boolean_function ?fct_isAtStructureEnd 0..1 pm#function_returning_a_structured_object ?fct_accessElement 0..1 pm#index ?index 0..1 pm#function_returning_an_index ?fct_nextIndex 0..1 pm#output_aggregation_function_for_structure_map ?fct_outputAggregation 0..1 pm#index ?outputIndex 0..1 pm#function_returning_an_output_aggregation_type ?outputAggregation_type 0..1 pm#structured_object ?future_output_structure, ) (pm#fct_applying_a_function_to_a_successor-based_structure = pm#fct_successor-based_map, pm#input: 1 pm#structured_object ?input_structure, 0..1 pm#function_with_input_a_structure_and_an_index ?fctToApply 0..1 pm#boolean_function ?fct_isAtStructureEnd 0..1 pm#function_returning_a_structured_object ?fct_accessElement 0..1 pm#function_with_input_a_structure_and_an_index ?fct_inputSuccessor 0..1 pm#output_aggregation_function_for_structure_map ?fct_outputAggregation 0..1 pm#function_returning_an_output_aggregation_type ?outputAggregation_type 0..1 pm#structured_object ?future_output_structure, ) } );
Plus un programme utilise des concepts/constructions abstraites, plus il sera
générique/réutilisable et paramétrable par le programmeur et l'utilisateur.
C'est plus simple avec des langages de haut niveau mais elles peuvent être définies
dans la plupart des langages. Exemple en C++ (explications données oralement) :
class ProcessParameters : public Associator //e.g., an associative array { //inherited methods : set, get, search, print, addToList, ... //e.g.: someProcessParameters.set({"inputMedium",stdin}); // someProcessParameters.set({ {"inputMedium",stdin}, {"outputMedium", stdout}}); public: ProcessParameters (Associator &a) { /* copy 'a' into 'this' */ } ProcessParameters (/*inP*/Medium ¶meterMedium, //"inP": input-only parameter Medium &inputMedium, //no need to write /*inP*/: it is the default Medium &outputMedium, Medium &errorMedium) { this->parameterMedium= parameterMedium; this->inputMedium= inputMedium; this->outputMedium= outputMedium; this->errorMedium= errorMedium; } }; class Process : Thing { public: ProcessParameters *pp; Process () { this->pp= new ProcessParameters(); } Process (ProcessParameters &processParameters) { this->pp= new ProcessParameters(processParameters); } Process (void *fct()) { this->pp= new ProcessParameters({"coreCall()",fct}); } void* run () //run the preCondition, then the coreCall, then the postCondition { if (!core_run("preCondition")) return NULL; void *returnValue= core_run("coreCall"); if (!core_run("postCondition")) return NULL; return returnValue; } void *core_run (const char *fctKind_name, bool isCondition) { void *errorFct()= pp->get("errorFct"); if (!errorFct) errorFct= fprintf; Medium *errorMedium= pp->get("errorMedium"); if (!errorMedium) errorMedium= stderr; void *fct()= pp->get(fctKind_name); if (!fct) return NULL; void *returnValue= (*fct)(pp); //the called functions have pp has unique parameter if (!returnValue && isCondition) (*errorFct)(errorMedium,"%s '%s' not satisfied",fctKind, fct->toString(pp)); return returnValue; } };
class InformationSelectionAndExploitation : Process { InformationSelectionAndExploitation () { ... //as in Process() } void* run () { Process *pr= pp->get("coreCall"); //normally, no coreCall is already set if (!pr) pr= pp->set("coreCall",this->coreCall); //defined below return pr->run(); //Process.run is called, not this one } void* doNothing () { return NULL; } void* coreCall () { Process *selectionLoopInitialization= pp->get("selectionLoopInitialization"); if (!selectionLoopInitialization) selectionLoopInitialization(doNothing()); Process *selectionLoopFilter= pp->get("selectionLoopFilter"); if (!selectionLoopFilter) selectionLoopFilter(doNothing()); Process *selectionLoopStepIfNotAtEnd= pp->get("selectionLoopStepIfNotAtEnd"); if (!selectionLoopStepIfNotAtEnd) selectionLoopStepIfNotAtEnd(doNothing()); Process *selectionLoopAction= pp->get("selectionLoopAction"); if (!selectionLoopAction) selectionLoopAction(doNothing()); for ( selectionLoopInitialization->run(); selectionLoopFilter->run(); selectionLoopStepIfNotAtEnd->run() ) { pp->addToList("results",pp->selectionLoopAction->run()); } return (pp->get("results")); } }; class Xfct1_1 : InformationSelectionAndExploitation { Xfct1_1 () { if (!pp->selectionLoopInitialization()) pp->set("selectionLoopInitialization", directoryExplorationStartingFromCurrentDirectory); if (!pp->selectionLoopStepIfNotAtEnd()) pp->set("selectionLoopStepIfNotAtEnd", depthFirstDirectoryExplorationExceptForSymbolicLinks);; //by default, no filtering : //if (!pp->get("selectionLoopFilter"))) // pp->set("selectionLoopFilter",doNothing()); if (!pp->get("selectionLoopAction"))) pp->set("selectionLoopAction",display_nbBytes_nbWords_nbLines_of_parameter); } };
Toutes les parties de processus/programme, et leur interactions, peuvent se définir en
logique via des ontologies. En voici une adaptée au début de la phase de modélisation ou au
partage de connaissances (raisons et guides donnés en section 1.0, e.g., en section 1.0.7).
process input : 1..* (information //below, within "(. )": any input_medium, not just the 1..* medium: 1..* (. input_medium > (input_file > parameter_file stdin) graphical_interface command_line_parameter ) ), input_medium: 1..* input_medium, //irrelevant here but good for parametering purposes (see next page) output: 1..* (information medium: 1..* (. output_medium > (output_file > stdout stderr) graphical_interface ) ), > (information_selection_and_exploitation part: 1..* (. information_selection_process < process, //selection = exploration + filtering part: 1..* information_exploration_process //e.g., directory traversal with 'find' 1..* information_filtering_process //e.g., file selection with 'find' ) 1..* information_exploitation_process, > Xfct1 //actually, as reminded in the next page, like the command 'find', Xfct1 is an // information_selection_and_exploitation process that embeds other ones, e.g., ); // 'selecting files' is one, 'selecting characters/words/... within a file' is another information_exploration_parameter_description < description, //+ idem for filtering description of: a (. information_exploration_parameter > (info_exploration_starting_point =< collection) //any collection can be used (info_exploration_method < process, > depth_first_exploration breadth_first_exploration ) (info_exploration_depth < integer) (info_exploration_constraint < state //collection of the states in which certain // objects (e.g., directory files) should be if they are to be explored, e.g., // E.g., a state specifying the type, creation/update date and access permission ) // of a file );
Dans l'ontologie précédente, Xfct1 aurait pu être plus détaillée.
Toutefois, si le but est
simplement de réutiliser cette ontologie comme un
fichier de paramètres pour un programme,
- de nombreuses relations dans l'ontologie vont être inutiles, d'autres vont
manquer (e.g., à la
page précédente, "input_medium" est
un raccourci qui permet de gagner quelques lignes de
code dans la paramétrisation d'un programme)"
- des langages moins expressifs (et beaucoup moins adéquats pour la
modélisation et le partage
de connaissances) - en fait, la plupart des langages de description de structure de données -
peuvent être utilisés, e.g., XML ou JSON.
JSON est la notation de
Javascript - et d'un certain nombre d'autres langages - pour décrire
des structures de données. Il est beaucoup plus concis que XML et sera un jour probablement
plus utilisé que XML, au moins en programmation. Sa syntaxe ressemble à celle FL (le langage
que vous utilisez depuis le début de l'année scolaire) mais il est insuffisant pour la
modélisation
et le partage de connaissances.
Exercice (après avoir étudié JSON et lu la section 1.0):
pourquoi est-il insuffisant pour cela ?
Comme connaître JSON vous sera utile (étudiez le !) et qu'il est suffisant pour décrire des
des fichiers de paramètres, la page suivante donne un exemple du contenu d'un tel fichier en
JSON (au lieu de FL) pour un programme qui l'exploite afin d'implémenter de manière flexible
les fonctions principales de Xfct1
(cliquez ici pour l'arcane d'un tel programme).
Plus précisément, l'exemple est en
JSON-LD car c'est la version de JSON
conçue par le
mouvement pour les Linked Data (LD) - i.e., pour le Web Sémantique - et c'est
donc une
version plus précise et expressive que la plupart des autres.
Il serait assez simple de construire, par exemple en "XML (schema)" un "schéma de document"
(Document Data Type) pour les structures utilisables dans un tel fichier de paramètres.
Comme une "ontologie de paramètres de programme" (ontologie pour la phase
d'opérationalisation donc, pas pour la phase de modélisation), ce schéma définirait le
termes (types et valeurs/instances) utilisables dans le programme pour sa paramétrisation.
Toutefois, comme la liste de ces termes peut être aisément déduite de l'exemple en
page suivante, un tel schéma n'est pas ici donné. L'entête du programme peut faire
référence à un fichier de paramètres dont les commentaires permettent de dériver
les différentes possibilités, au lieu de faire référence à un tel schéma/ontologie.
Un but du schéma (ou de l'ontologie) sous-jacent(e) à ce fichier est de pouvoir traiter
tous les processus de "selection et exploitation" de la même manière, e.g.,
- l'exploration et sélection de fichiers dans un répertoire (option prise ci-dessous) ou
de nœuds dans un(e) liste/tableau en mémoire (option en commentaires dans le programme exemple)
- la sélection de caractères, mots, lignes, ... dans un fichier non-répertoire ou une liste.
{ "@type": "process",
"input_medium": "stdin", //warning: "stdin" is a string; a program needs to recognize
//this keyword and replace it with the "standard input" object
"normal_output_medium": "stdout", "error_output_medium": "stderr",
"mainFct":
{"@id": "Xfct1", //for clarity purposes only (the program does not use "@id" attributes)
"@type": "info_selection_and_exploitation", //1st, the selection of files
"info_exploration_content_type": "directory", //or: "within_a_file", "list", ...
"info_exploration_content": "/usr/lib/", //example for "directory" above
//"info_exploration_content": "{a b {c d e {f} g} h i}", //example for "list" above
"info_exploration_method": "depth_first_exploration",
"info_exploration_depth": -1, //no exploration depth limit
"info_exploration_positive_constraint":
{"@type": "file_directory"}, //no other constraint (e.g., on creation dates, ...)
"info_exploration_negative_constraint":
{"@type": "symbolic_link"}, //symbolic links should not be explored/traversed
"info_filtering_positive_constraint": [], //none
"info_filtering_negative_constraint": [ {"@type": "file_directory"} ],
"info_exploitation_process_on_selected_info":
{"@id": "selection_and_exploration_of_each_selected_file",
"@type": "info_selection_and_exploitation",
"info_exploration_content_type": "within_a_file", //binary/textual file
//"info_exploration_content" not used here since the file is selected as above specified
"info_exploration_starting_point": 0, //the beginning
"info_exploration_method": "sequential", //goes to the next character/record at each step
"info_exploration_depth": -1, //if the file is an index, explore the indexed file
"info_exploration_positive_constraint": {}, //all characters/records are considered
"info_exploration_negative_constraint": {}, //all
"info_filtering_positive_constraint": {}, //an index file also belongs to the selection
"info_filtering_negative_constraint": {"@type": "index_file"},
"info_exploitation_process_on_selected_info":
{"@id": "Xfct1_exploitation_of_each_selected_character_or_record"
"input_medium": "menu", //to test inheritance overloading
"positionOfTheWordToDisplay": 10, "wordX": "hello", "maxNbWordXByLine": 12,
"display_of_nbBytes_average": "bold", "display_of_nbWords_average": "invisible",
"info_exploitationAtEnd": "Xfct1::exploitationAtEnd" //useless with a C/C++ program
} // unless the programmer associates the names with a function pointer;
} // in Javascript, this is done by the interpreter
}
}
Exercice de TD noté (1er envoi avant le 31/03/2014 ;
corrections orales le 31/03/2014 et 7/04 ;
envoi final avant lundi 14/04/2014) :
implémentation (seul ou en binôme) d'une solution "générique et
paramétrable"
pour Xfct1 ; pour vous guider,
l'arcane du programme en C++ vous est fournie ;
il vous faut le compléter aux endroits indiqués par les commentaires
"to be implemented" (+ "to be completed" dans l'entête).
D'autres recommandations sont données dans ce programme.
Veuillez utiliser l'anglais pour vos noms de variables et vos commentaires.
Vous pouvez utilisez d'autres languages que C++ mais il vous faudra alors re-écrire
le programme avant de pouvoir le compléter.
1 point sera enlevé pour toute règle (donnée dans ce cours) non respectée.
Toutefois, pour ce programme, la règle des "70 caractères maximum par ligne" est
remplacée par "100 caractères maximum par ligne".
Vous êtes invités à poser des questions (sur le sujet et vos programmes).
Vous devez appliquer les règles dès l'écriture de vos programmes,
pas dans une 2nde phase.
Pour des raisons d'efficacité, votre environnement de travail (disposition de vos
fenêtres, ...)
ne doit pas vous obliger à le modifier
(-> pas de fenêtre l'une sur l'autre, pas de
nécessité d'iconification/ouverture, ... ;
à titre d'exemple, voyez les différences entre
ce poisson et
ce poisson
dans la même fenêtre puis dans deux fenêtres côte à côte ;
-> avantage des fenêtres côte à côte pour la détection de bugs,
la compréhension, ...
-> avantage d'avoir un code concis).
Pour faciliter mes contrôles/aides durant vos TPs, mettez votre éditeur de texte sur la
partie droite de votre écran et les entrées-sorties de votre programme sur la partie gauche.