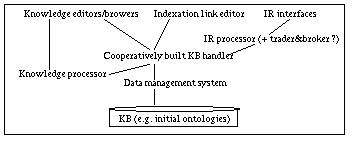
Fig. 1. The WekKB tools data flow
Philippe
MARTIN
University of Adelaide -
Computer Sciences department, Australia
e-mail: pm .@. phmartin dot info
This extended abstract has been accepted at the
CGTools workshop of
ICCS'97
(Fifth International Conference on Conceptual Structures, University of Washington,
Seattle,
August 4-8, 1997) and is included in the ICCS'97 proceedings.
The World Wide Web (WWW) provides a simple means for users to make information
available to others and to retrieve information by navigation.
Additional information retrieval (IR) or collaborative facilities must be provided by
servers. For example:
- net search servers for document retrieval by query, back-link capabilities, etc.;
- annotation servers for storing public/group annotations (e.g. comments,
critics, indexations and relations) on (parts of) documents;
- filtering servers for controls on document content, form or sequence
of desired document, e.g. for document aggregation, link indirection and
selective access/display.
However, specific information is difficult to retrieve on the WWW. Net search servers only enable document retrieval and not knowledge retrieval because they do not represent the semantic content of documents. Similarly, hypertext links between documents or document annotations only support document retrieval. The smaller the indexed pieces of information are, and the more semantically organised they are, the more the IR system may provide precise answers, answers to queries expressed at different levels of generality, or organised views of documents content.
The WebKB set of tools is aimed to
- allow users to index any document element (DE) on the WWW
(e.g. a document or one of its words) by arbitrary precise annotations,
e.g. comments, knowledge representations or relations to other DEs,
- guide the building of precise DE representations,
- ease the access, display, modification and comparison of knowledge in a
cooperatively built knowledge base (which may be a base of DE annotations),
- allow users or programs to do these operations remotely, e.g. via a WWW-browser,
- exploit such knowledge and indexation of DE by knowledge for generating documents
answering precisely searches by query or navigation.
Various modules or tools are necessary to obtain the previous functionalities, at least an HTML editor, a knowledge editor, an indexation link editor, knowledge/data bases, a data management system, a cooperatively built knowledge base handling system, a knowledge processor (inference tool), an IR processor, IR interfaces and a WWW-browser. A trader and a broker could also be added. A trader is meant to automatically find adequate knowledge/data bases to be exploited for answering information requests. A broker handles the exchange of information between the IR processor and knowledge/data bases having different information access protocols. The next figure shows dependencies between such modules or tools.
Fig. 1. The WekKB tools data flow
We have chosen to build separate, combinable and WWW-accessible tools. Thus, users may easily use them and exchange any of them with a tool they think more interesting (they only need to change the tool URL address; of course, if the first tool follows a special protocol, its substitute must follow the same protocol). They may save the outputs of a tool in files (which may then be used as inputs to other tools) or they may directly copy and paste the outputs into text entries of other tools.
Whenever possible, we have used HTML and Javascript in our tool implementation to allow users to easily customize their interface and behavior by modifying the HTML sources. As opposed to CGI servers (servers using the Common Gateway Interface), Javascript programs are directly executed on client machines (and at present more safely than Java programs). This implementation choice has the drawback that it restricts the usable WWW-browsers.
The WebKB set of tools will include at least the following components:
- a conceptual graph (CG) textual editor (already implemented in Javascript);
- an ontology editor for the edition of type definitions or relations between types
and/or individuals, and a hierarchy browser for such relations;
- an indexation link editor (already implemented in Javascript);
- a CGI server and a Java server allowing the use a data management system;
- a cooperatively built knowledge base handling system (for that, we will implement the
protocols we have described in the annexe 2 of [6]);
- the WordNet natural language ontology superseded by a top-level concept type
ontology useful for knowledge representation and knowledge acquisition [4,6];
- a relation type ontology which merges various relation types ontologies,
e.g. thematic, spatial, temporal and argumentative relation type ontologies [4,6].
- a CGI server allowing the use of the CG processor Peirce [1];
- a CGI server for the generation of documents (IR processor; this CGI server,
as well as the previous one, might be reimplemented in Java for efficiency reasons);
- a javascript IR interface showing the results provided by the IR processor.
The WebKB set of tools have a broad range of applications: precision-oriented IR, knowledge acquisition (KA), computer supported cooperative work (CSCW).
We show in CGKAT [4,5,6] (also see our presentation of CGKAT in these CGTOOLS'97 proceedings) how ontologies and the combination of a structured document editor and a CG workbench can ease KA and IR. The WebKB set of tools reuses the underlying philosophy of CGKAT but is WWW-based, more easily extensible and customisable, and may exploit efficient tools such as databases. Similarly to CGKAT structured documents, HTML documents are used for organizing knowledge and data and displaying them (knowledge-based document generation). Although current WWW-browsers/ editors do not yet have all the facilities provided by the structured document editor used in CGKAT (e.g. graph editing, index generation, zoom, views handling), they include more and more similar facilities, e.g. DE presentation models (style sheets), and provide other ones (e.g. navigation history management and script languages).
The combination of facilities allowed by the WebKB set of tools (or similarly based set of tools) will probably allow users to develop applications that were previously too costly. The two most important facilities for KA and CSCW that the WebKB set of tools is aimed to provide are 1) some knowledge-based comparison and synthesis of information provided by different authors, and 2) the user control of generated document content, form or sequence via document descriptions using HTML, Javascript and conceptual queries.
We do not intend to integrate in the WebKB set of tools facilities which are not based on knowledge handling or structured document handling, e.g. automatic indexation of documents, hypertext network visualisation and real-time interaction between users. However, the WebKB set of tools may easily integrate tools designed by others.
The WebKB set of tools is intended to combine various technologies for helping KA, IR and CSCW, notably the WWW-related technologies, the databases and the knowledge representation languages and processors. To do so, we rely on our previous experience in the development of CGKAT. The WebKB home page is at www.webkb.org.
The WebKB set of tools shares many goals and design principles with current WWW-based public annotations tools, e.g. ComMentor [8] and HyperNews [2], and WWW-based traders, e.g. AlephWeb[9], NetRepository [3] and AI-trader [7]. However, such annotation tools are not intended to index DEs by knowledge (they cannot exploit it for IR), and HyperNews, AlephWeb and AI-trader only allow the user to index documents, not arbitrary parts of them. AI-trader uses CGs for indexing documents, while NetRepository uses KIF for communications between knowledge servers. None of these tools can generate documents as answers to user queries.
1. G. Ellis, Managing Complex Objects. Ph.D thesis, Queensland University (Computer Sciences Dept.), Australia, 1995.
2. D. LaLiberte, Collaboration with HyperNews, in Proceedings of Workshop on WWW and Collaboration, Cambridge, MA, September 11-12, 1995.
3. C. Luigi Di Pace, P. Leo, and A. Maffione, NetRepository: A Networked Information Repository which Supplies Ontologies for Retrieving Information, in Proceedings of ICCS'97, University of Washington, August 4 - 8, 1997
4. P. Martin, Using the WordNet Concept Catalog and a Relation Hierarchy for KA, in Proceedings of Peirce'95, Santa Cruz, California, August 18, 1995.
5. P. Martin and L. Alpay, Conceptual Structures and Structured Documents, in Proceedings of ICCS'96, Sydney, Australia, August 19-22, 1996.
6. P. Martin, Exploitation de graphes conceptuels et de documents structurés et hypertextes pour l'acquisition de connaissances et la recherche d'informations. Ph.D thesis, University of Nice - Sophia Antipolis, France, October 14, 1996.
7. A. Puder, S. Markwitz, and F. Gudermann, Service Trading Using Conceptual Structures, in Proceedings of ICCS'95, Santa Cruz, California, August 14-18, 1995.
8. M. Röscheisen, C. Mogensen, and T. Winograd, Beyond Browsing: Shared Comments, SOAPs, Trails, and On-line Communities, in Proceedings of the Third International World-Wide Web Conference in Darmstadt, Germany, April 1995.
9. G. Rodríguez, and L. Navarro, AlephWeb: a CSCW Large Scale Trader. http://www.pangea.org/alephweb.aleph/paper.html